What Happens When You Hit a URL in Your Browser
Let me walk you through exactly what's happening when you type https://www.google.com/api/search?q=home and hit enter. This is the kind of stuff that, once you understand it, makes you appreciate how much heavy lifting the internet does for us every single day.
Understanding URLs: The Address System of the Internet
Before we dive into the process, let's break down what constitutes a URL. A URL is basically a human-readable way to know what we are interested in - it's our map to navigate the web.
Looking at https://www.google.com/api/search?q=home, here's what each piece means:
https- This is the scheme. It tells the browser which protocol to use while connecting to the server. Other schemes includehttp,ws(WebSocket),wss(WebSocket Secure), etc.www.google.com- This is the domain we want to connect to. It's the human-readable address of the server./api/search- This is the path. It tells the server which specific resource we're interested in accessing.?q=home- These are query parameters - optional key-value pairs we can pass to provide additional information in the request.
The beauty of this system is that it gives us a human-readable way to specify exactly where we want to go and what we want to do. But here's the thing - machines don't actually understand domain names. They need IP addresses.
The DNS Resolution: Converting Names to Numbers
Why do we need DNS resolution? Every machine on the internet has an "address" enabling us to reach it over the network - this is the IP address. But it's much easier to remember "google.com" than "17.53.21.253", right?
Hence, we need a way that converts google.com → 17.53.21.253. This process is called DNS resolution.
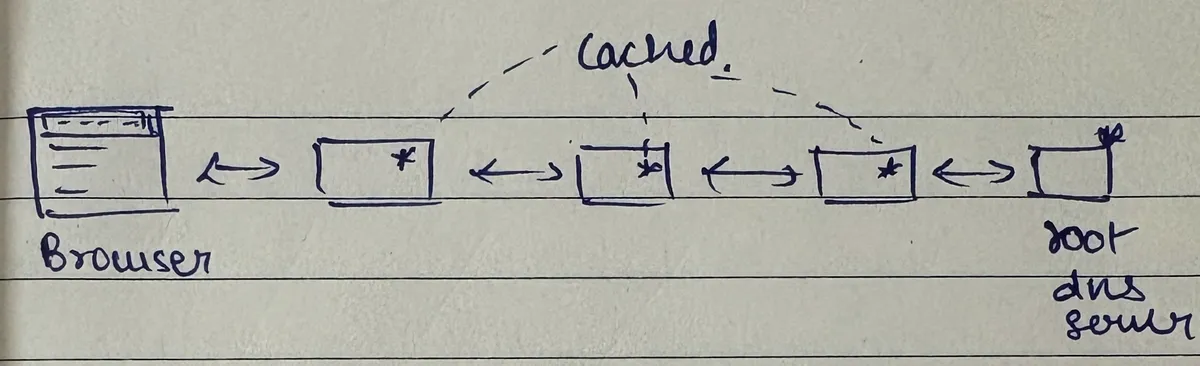
Here's what actually happens during DNS resolution:
The browser does a DNS lookup to get the associated IP address. What looks like a simple call actually involves lots of machines working together in an iterative process. Your request might go through:
- Local browser cache - DNS information is heavily cached in the browser
- Operating system cache - The OS caches this across all machines
- Root DNS servers - The authoritative source for all DNS information
- TLD servers - Top-level domain servers (for .com, .org, .in, etc.)
- Authoritative name servers - The final authority for specific domains
- [Reference to other DOC DNS]
Key insight: DNS information is heavily cached at every layer - in the browser, in the operating system, across all machines involved in DNS resolution. This is why subsequent requests are served much faster.
After this resolution process, the browser has the IP address to connect to.
Establishing the Connection: TCP Handshake
Once the browser has the IP address (17.53.21.253 in our case), it can now establish a connection. Since we're using HTTPS, the browser now establishes a TCP connection with the machine (server) and can now talk to it over the network.
But here's where it gets interesting - this isn't just connecting to a single server. This is actually connecting to a huge infrastructure that might include:
- Load balancers
- API gateways
- Multiple servers
- Service meshes
This in itself is a Pandora's Box and consists of 1000s of machines. [I will write more about this later]
For now, the core idea is: your browser can now establish a connection with this machine, and internally it might go to some other machines across multiple layers.
Sending the Request: HTTP in Action
Now that the TCP connection is established, the browser now compiles the request into HTTP specification and sends it across to the server.
Since we're just hitting a URL in the browser, it defaults to an HTTP GET request. The browser creates an HTTP message that looks like this:
GET /api/search?q=home HTTP/1.1
Host: www.google.com
Connection: keep-alive
Let me break this down:
GET- The HTTP verb (other protocols are possible)/api/search?q=home- The path and query parametersHTTP/1.1- The HTTP protocol version- Headers - Additional metadata and instructions to the server
HTTP is a protocol that specifies:
- How to pack the data
- What to do before, during, and after the request
[Write another blog here for HTTP and Protocols]
Given we are just hitting a URL in the browser, it fires an HTTP GET to the server.
Server Processing: The Business Logic
Once the server receives the HTTP request, it parses the above message and understands what needs to be done.
The server may:
- Load a file from local disk and serve it
- Make a call to database to get response
- Throw an error if malformed
It compiles a proper HTTP response and responds back over the same TCP connection.
A typical HTTP response looks like:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 2042
<html><head>....... ~ body
Let me explain each part:
200- Status code (everything went OK)Content-Type: text/html- Type of content being returnedContent-Length: 2042- Length of the response body<html><head>......- The actual HTML body
Browser Rendering: Bringing It All Together
Browser upon receiving the response parses the message, extracts the info, and "renders" it.
The browser looks at the response and sees:
- Status code - Was the request successful?
- Content-Type - How should I handle this content?
- Body - What should I actually display?
Since the content type is text/html, the browser knows to render this as an HTML page. If the browser does not support the response type, then it downloads the file locally instead of trying to render it.
But here's where it gets really interesting - when HTML is rendered, the browser may come across:
- Linked CSS files - It fetches the additional files by going through the same process
- IMG tags to render an image - Same HTTP flow for each image
- Inline JavaScript code - It starts executing it, which may involve making more HTTP requests
For each of these additional resources, the browser repeats this entire process - DNS lookup (if needed), TCP connection, HTTP request, response processing, and rendering.
The Complete Picture
What looks like a simple call actually involves lots of machines working together. This is a very 10,000-foot view of what happens when you hit a URL in your browser.