05 DEC 2025 · 20 MIN READ
scaling reads
scaling reads sounds boring on the tin and then you realize it's basically every system design problem in disguise. the moment your app gets even a little popular, reads outpace writes by 10×, then 100×, then 1000× — and your single database starts crying. this post walks through the actual ladder you climb to handle it: from "just add an index" all the way up to global CDNs, with the trade-offs that bite you at each rung.
think about your instagram feed. you open the app, and bam — dozens of photos, each one pulling its own metadata, user info, like counts, comment previews. one feed load might fire 100+ db queries. meanwhile what'd you actually do? you posted one photo. that's a single write. one tweet → thousands of reads. one product upload → hundreds of browses. youtube serves billions of video views per day on top of millions of uploads. textbook ratio starts at 10:1 reads-to-writes but content-heavy apps are prolly looking at 100:1 or 1000:1.
and here's the problemmmm — when reads pile up, your db isn't slowing down because of bad code. it's physics. CPU cores execute a finite number of instructions per second, RAM holds a finite amount, disk I/O is bounded by what the SSD can physically push. when you hit those walls, no amount of clever code is gonna help. you've gotta change the architecture.
what you'll take away
quick pointers so you know what to look for as you read:
- reads always outgrow writes. plan the system around reads first.
- start cheap, climb only as far as you need. indexes → denorm → replicas → cache → CDN.
- composite + covering indexes beat denormalization most of the time. cheaper, simpler, no consistency drama.
- replicas buy throughput, caches buy latency. different problems, different tools.
- cache invalidation is where the bodies are buried. TTL is a safety net, not a strategy.
- physics wins eventually. at extreme scale you need versioned keys, request coalescing, probabilistic refresh.
- the right answer is sometimes "we don't need to scale yet." modern hardware is wild.
the ladder
read scaling is a ladder. each rung adds operational pain in exchange for more throughput:
- optimize within your db — indexes, composite/covering indexes, denormalization
- scale horizontally — read replicas, then sharding when you must
- add caches — Redis/Memcached, then CDNs at the edge
let's walk it.
optimize within your database
before you reach for new infrastructure, your existing db almost always has more headroom than you think. modern postgres or mysql is not a toy — with the right schema and indexes you can squeeze tens of thousands of QPS out of a single box.
indexes — always step one
an index is just a sorted lookup table that points back into your real data. think of the index in the back of a textbook — instead of flipping every page hunting for "B-tree", you check the index, see "page 184", jump straight there.
without one, your db does a full table scan — reads every row to find what you're after. with one, it jumps directly. that's O(n) becoming O(log n) — the difference between scanning a million rows and checking maybe 20 entries in a tree. most general-purpose indexes are B-trees. there are specialized ones — hash for exact matches, GIN/GiST for full-text or geo — but B-tree is your default.
so the first move for any read scaling problem? add indexes on the columns you query, sort by, or join on. social app filters posts by hashtag → index hashtag. sort products by price → index price. dead simple.
old textbooks freak out about "too many indexes slowing down writes." this fear is way overblown for modern hardware. yes there's some write overhead per index, but under-indexing kills more apps than over-indexing ever will. add the indexes you need. don't be cute about it.
composite + covering indexes — the cheaper alternative to denormalization
before you reach for denormalization (which is messy, more in a sec), see whether a composite index can solve it first. composite means an index across multiple columns. great for queries that filter or sort on more than one thing.
SELECT post_id, post_title FROM posts
WHERE user_id = ? AND created_at > ?
ORDER BY created_at DESC;a composite index on (user_id, created_at) lets the db satisfy the entire WHERE and the sort using just the index. push it further with a covering index — (user_id, created_at, post_title) — and the index contains every column the query needs. the db doesn't even touch the table. people call this an "index-only scan" and it's stupidly fast.
a few rules. column order matters — put the most selective filter first. (user_id, created_at) helps queries on user_id alone, but not on created_at alone. sort order is free if you align it — if your ORDER BY matches the column order in the index, the db skips the sort step entirely. and don't over-cover — every column inflates write cost and storage.
why does this matter? because composite/covering indexes often kill the need for denormalization. denormalization brings storage bloat AND consistency headaches. a composite index brings just write cost. that's a way better trade. try this first. denormalize only when no index can satisfy the query.
hardware — boring but it works
sometimes the answer is just bigger hardware. swap spinning disks for SSDs, get 10–100× faster random I/O. add RAM, more of your dataset stays in memory. add cores, handle more concurrent queries.
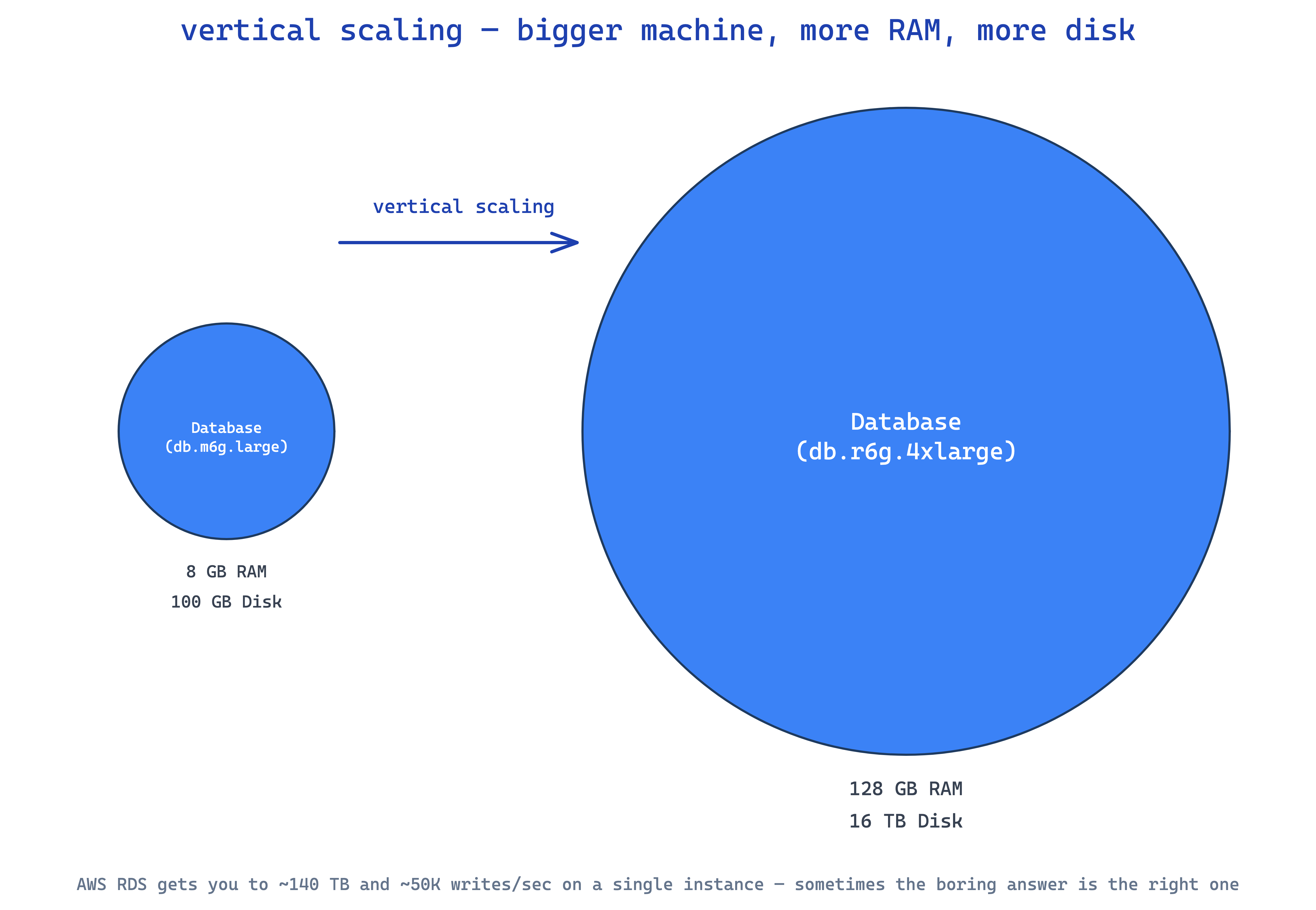
won't solve every problem but it buys breathing room, fast. real limits though — you'll hit the ceiling on the biggest box your cloud provider offers, and a single failure takes the whole thing down. it's a stopgap that buys time to do the real architectural work.
denormalization — when no index can save you
normalization splits data across tables to avoid duplication. nice for storage, ugly for reads — joins everywhere. for read-heavy systems where joins start eating CPU, denormalization flips the script: you intentionally duplicate data to make reads single-table.
classic e-commerce. normalized version joins users, orders, order_items, products:
SELECT u.name, o.order_date, p.product_name, p.price
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
WHERE o.id = 12345;four tables, three joins. fine at small scale, painful at thousands of order pages per second. denormalized: just have an order_summary table with everything inline.
SELECT user_name, order_date, product_name, price
FROM order_summary
WHERE order_id = 12345;one table, one row, done.
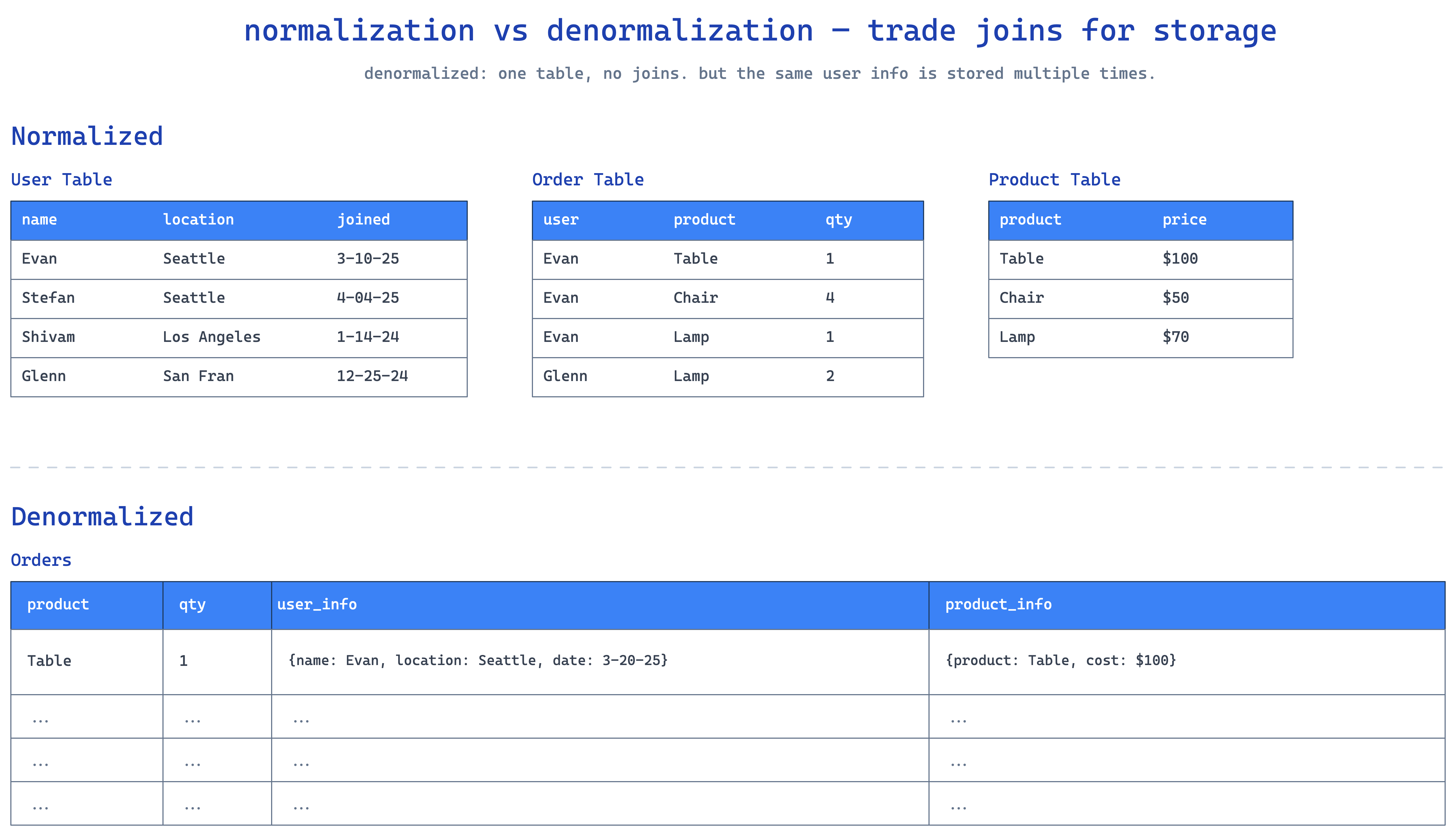
yes you're storing the user name redundantly. yes that's storage cost. for a read-heavy system that's often worth it. the catch — when a user changes their name, you've gotta update it everywhere. that's the consistency tax, and every place a denormalized field lives is a place that can drift out of sync if your write path has a bug.
rule of thumb: only denormalize when reads vastly outnumber writes. if writes are frequent the consistency complexity prolly isn't worth it.
materialized views are denormalization for aggregations — instead of recomputing the average rating on every product page load, you precompute once and store the result. typically refreshed by a background job.
CREATE MATERIALIZED VIEW product_ratings AS
SELECT p.id, AVG(r.rating)
FROM products p
JOIN reviews r ON p.id = r.product_id
GROUP BY p.id;✽ RECALL your joins are eating cpu on a read-heavy table. why try a covering index before reaching for denormalization?
a covering index puts every column the query needs into the index itself — the db does an index-only scan and never touches the table. that buys most of denormalization's read win at the cost of just some write overhead, while denormalization adds storage bloat plus a consistency tax: every duplicated field is a place that can drift out of sync. denormalize only when no index can satisfy the query.
scale your database horizontally
at some point one machine isn't enough. rough rule of thumb: above about 50–100k indexed reads per second , you've gotta either add a cache or distribute across more boxes. exact numbers vary based on hardware and query patterns, but that's the ballpark.
read replicas — leader/followers
simplest horizontal play. you keep your primary db (the leader) handling all writes, spin up extra copies (followers) that get every write replicated to them. reads can go to any follower. read throughput multiplies.
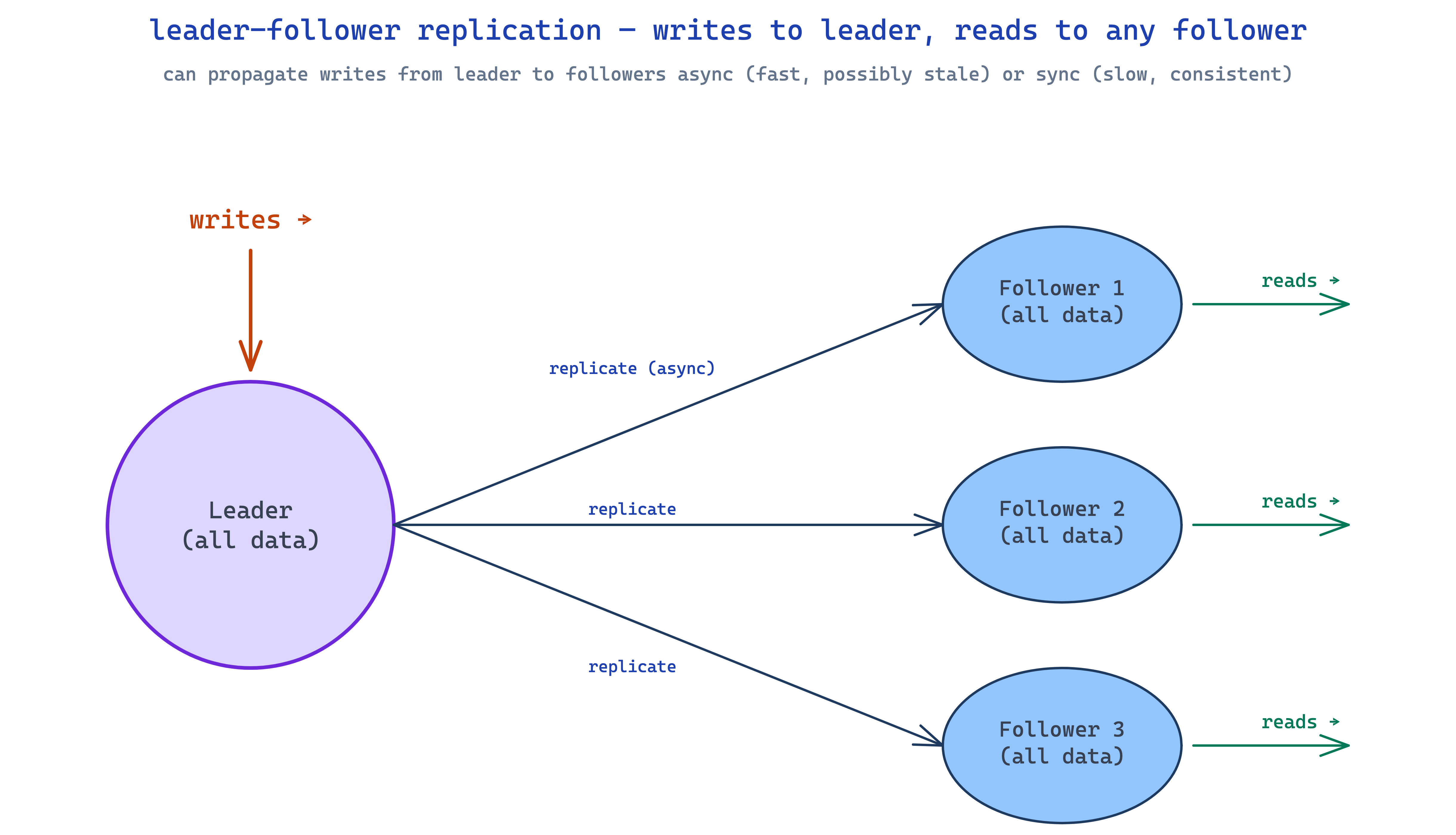
bonus: redundancy. if the leader dies, you promote a follower. minimal downtime.
the trade-off is replication lag. when you write to the leader, it takes some time before followers see that write. read-your-own-write becomes weird — a user updates their profile, the request hits a follower that's a beat behind, and they see their old name. classic gotcha.
so you've got a choice. synchronous replication — leader waits for followers to confirm before acking. fully consistent, but writes are bottlenecked by the slowest follower. asynchronous — leader acks the write, replicates in the background. fast writes, real lag window. most production systems are async by default and just accept the staleness. the ones that need fresh reads after writes route critical reads back to the leader.
sharding — when one box can't even hold the data
read replicas help when throughput is the issue. they don't help when the dataset is the issue. if you have 50TB of data and a single instance can't even store it, you need sharding — splitting the data itself across multiple databases. two common ways:
functional sharding — split by domain. user data in one db, product data in another, likes in a third.
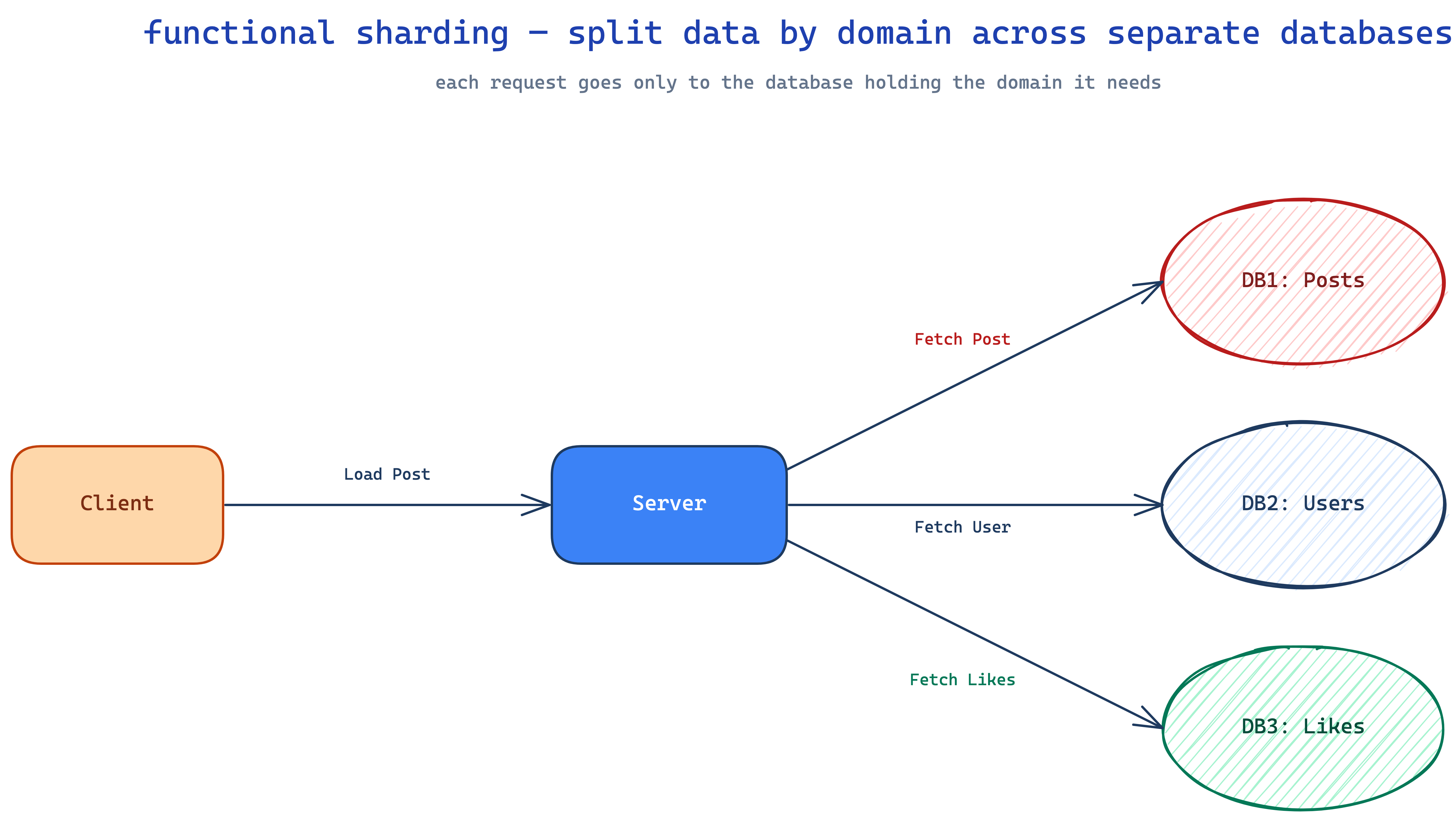
geographic sharding — split by region. US users in US dbs, EU users in EU dbs. lower latency, less load on any single instance.
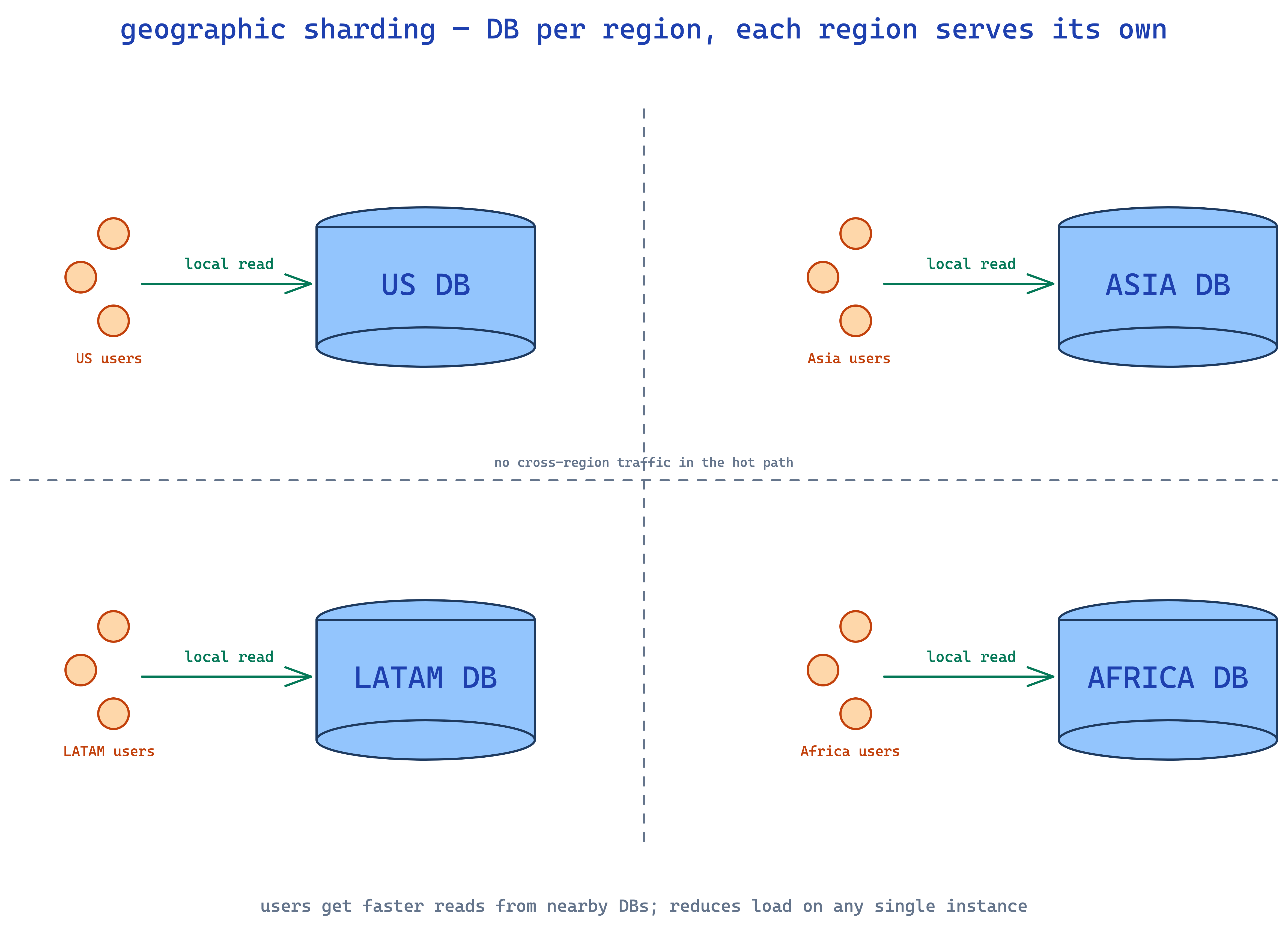
real talk though: sharding is operationally a beast — cross-shard queries, rebalancing pain, distributed transactions, hot shards. it's primarily a write scaling technique. for read scaling specifically, caching is almost always the better play.
✽ RECALL a user updates their profile and immediately sees their old name. what happened, and what are your options?
replication lag — the read hit an async follower that hadn't applied the write yet. you can go synchronous (fully consistent, but every write waits on the slowest follower), or stay async and route read-your-own-write critical reads back to the leader. most production systems pick async plus selective leader reads, accepting staleness everywhere else in exchange for fast writes.
add caches
you've optimized the db, you've added replicas. you still need more. now you reach for cache.
most apps have heavily skewed access patterns. millions read the same viral tweet. thousands hit the same popular product. the same trending video gets pulled millions of times. you're literally executing the same query over and over to return the same result. that's a caching layup.
caches store hot data in memory. databases read from disk and run query planners. caches just hand you the bytes back. the gap is sub-millisecond cache reads vs tens of milliseconds for even a well-tuned query. orders of magnitude.
application-level caching — Redis or Memcached
stick a Redis or Memcached instance between your app and your db. on every read, check the cache first. hit? return immediately. miss? query the db, populate the cache, return.
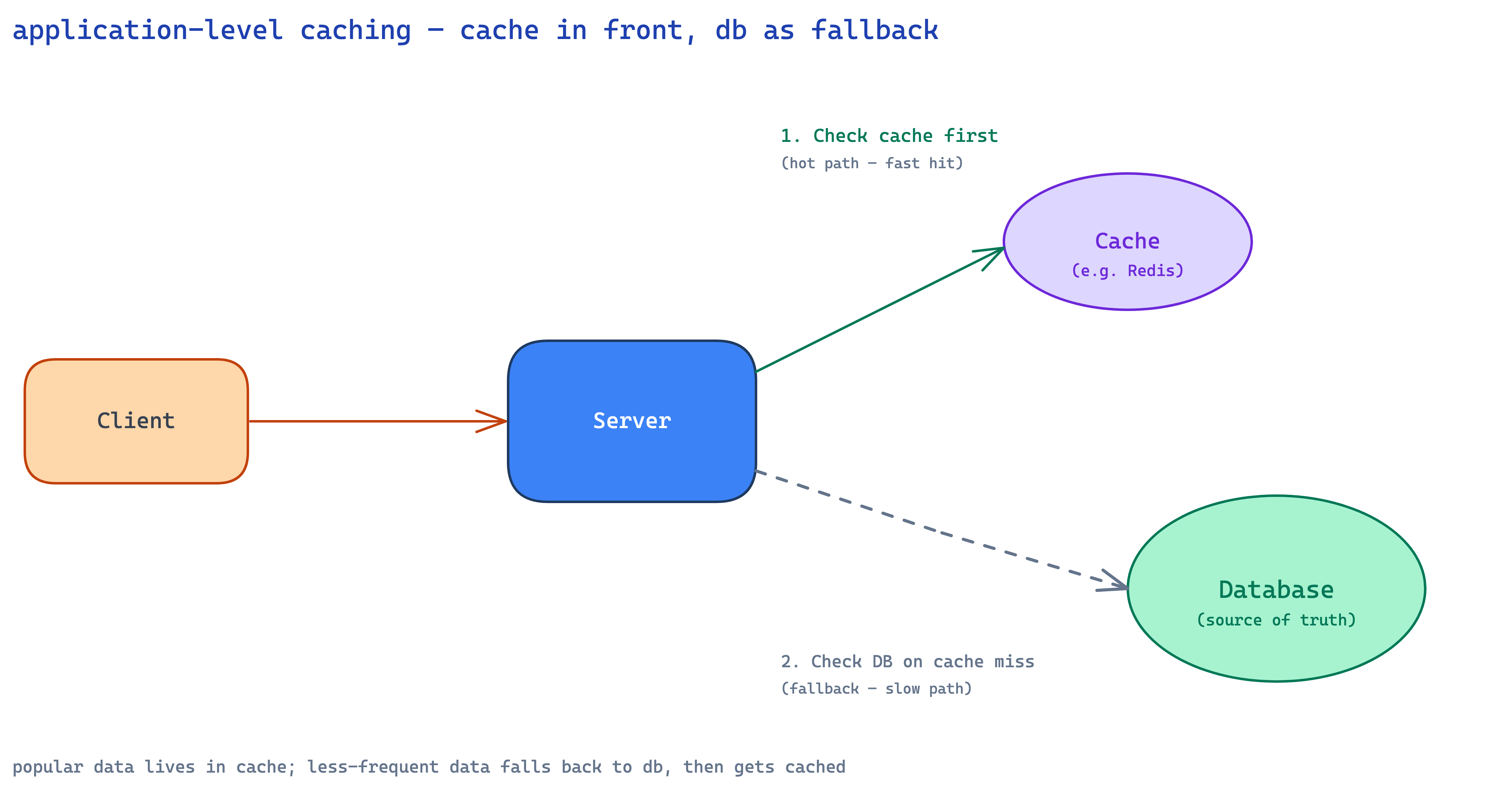
popular data naturally stays hot. celebrity profiles get hit constantly so they live in cache forever. inactive profiles get cached only when accessed and expire after their TTL. the system self-tunes.
now the hard part. cache invalidation is genuinely one of the trickiest things in software. when underlying data changes, you've gotta make sure the cache doesn't keep serving the old version. main strategies:
- TTL — fixed lifetime per entry. simple, but you accept staleness up to the window. great for data with predictable update cadence.
- write-through — delete or update the cache the moment you write to db. consistent, but adds latency to every write and you've gotta handle the case where db write succeeds but cache invalidation fails.
- write-behind — queue invalidation events, process async. faster writes, brief stale window.
- tagged — group entries by tag (
user:123:posts), invalidate by tag when related data changes. powerful but you've gotta track relationships. - versioned keys — encode a version into the key. bump on writes, old entries become unreachable. clean, no race conditions — more below.
most production systems combine approaches. short TTLs (5–15 min) as a safety net plus active invalidation for critical data like profiles or inventory. low-stakes data (recommendation scores, view counts) can lean entirely on TTL.
drive your TTL from a product requirement. if the spec says "search results can be at most 30 seconds stale", your TTL is 30 seconds. let the requirement set the consistency budget.
CDN + edge caching
CDNs extend caching to globally-distributed edge servers. originally just for static assets — images, CSS, JS — but modern CDNs cache dynamic content too: API responses, query results.
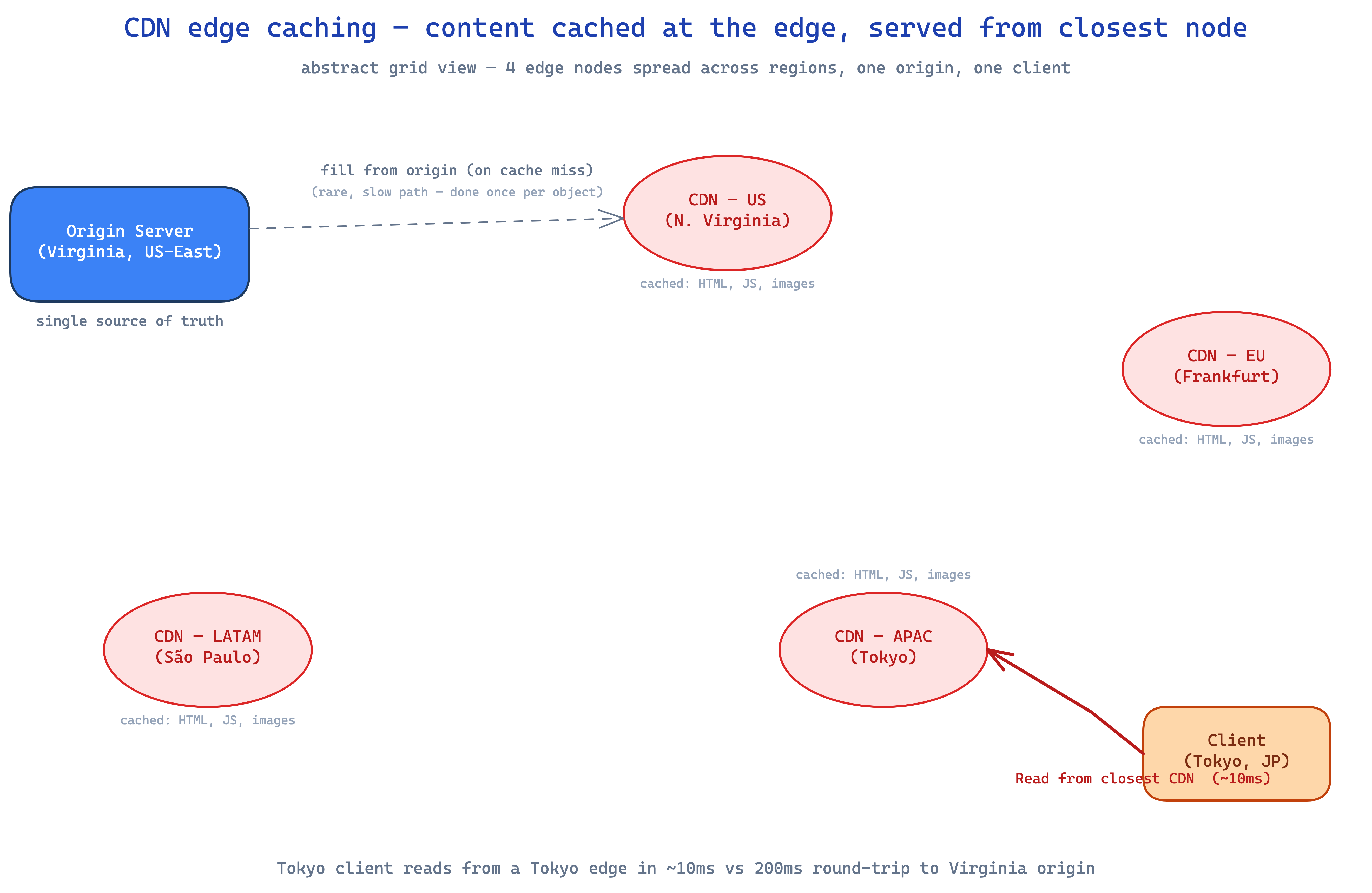
the latency win is dramatic. a user in tokyo hitting your origin in virginia is doing a 200ms round-trip. hitting a tokyo CDN edge? 10ms. that's a different category of fast.
for read-heavy apps, CDN caching can wipe out 90%+ of origin load. product pages, public profiles, search results — anything multiple people request — is a candidate. trade-off is invalidation across many edge locations, gnarly when you need it but worth the engineering for the win.
CDNs only make sense for content shared across users. don't cache user-specific stuff like personal settings or private messages — there's no hit-rate benefit when only one user ever requests it.
✽ RECALL you already have read replicas. what does a cache buy you that another replica doesn't?
latency, not just throughput — a cache hands back bytes from memory in sub-millisecond time, while even a well-tuned replica query pays disk reads and a query planner for tens of milliseconds. and access patterns are heavily skewed: millions of reads hammer the same viral content, so serving the identical result from memory instead of re-executing the same query is the whole win. replicas multiply query capacity; caches change the category of fast.
✽ RECALL why is "just set a TTL" not an invalidation strategy, and what do production systems actually do?
TTL alone means accepting staleness up to the full window for everything, including data where stale is unacceptable. production systems combine: short TTLs as a safety net plus active invalidation (write-through, tagged, or versioned keys) for critical data like profiles and inventory, while low-stakes data leans on TTL alone. and the TTL itself should come from a product requirement — "at most 30 seconds stale" means a 30-second TTL.
applying this in real systems
most production systems eventually need read scaling somewhere. the discipline is figuring out where. walk through your API endpoint by endpoint and identify the high-volume ones — that's where the work goes. start with query optimization, then caching, then replicas.
what makes a system robust is identifying read bottlenecks proactively , before the pager goes off. when sketching a new feature's API, pause at endpoints that'll get hammered. how often will this be called? does it need to be fresh? is the data shared across users? the answers tell you exactly which tools to reach for.
a few patterns that show up over and over:
- URL shorteners — extreme read/write skew. one URL shortened once, accessed millions of times. caching dream. cache the short→long mapping in Redis with no expiration, CDN globally.
- event ticketing — event pages get crushed when tickets drop. cache event details, venue info, seating charts aggressively. but never cache actual seat availability — you'll oversell.
- social feeds — pre-compute feeds for active users, cache recent posts from followed users. users mostly only read the first page so aggressive caching pays off.
- video platforms — cache metadata aggressively (titles, descriptions, thumbnails change rarely). view counts can be eventually consistent. CDN every thumbnail.
and where this whole playbook doesn't apply: write-heavy systems like Uber's location tracking or IoT sensors (focus on writes first), tiny scale where a single indexed db handles everything (don't over-engineer), strongly consistent systems like financial transactions (you can still cache, but with aggressive invalidation), and real-time collab like Google Docs (caching actively hurts).
✽ RECALL before adding any infrastructure, how do you decide where read-scaling work actually goes — and when is the answer "nowhere yet"?
walk the api endpoint by endpoint and find the high-volume ones, asking three questions: how often is it called, does it need to be fresh, is the data shared across users. then climb the ladder in order — query optimization, then caching, then replicas — without skipping rungs (check whether a composite index solves it for free before reaching for redis). and skip the playbook entirely for write-heavy systems, tiny scale, or real-time collab where caching actively hurts.
the gnarly edge cases
a few specific failure modes show up over and over once a system gets real traffic. worth knowing how to spot them.
"queries got slower as the data grew"
your app launched with 10k users and queries were instant. now you've got 10 million users and a simple lookup takes 30 seconds. CPU pinned at 100%. simple queries, nothing fancy.
the answer is almost always a missing index. without one, every query does a full table scan. 10 million rows scanned to find one user by email. multiply by hundreds of concurrent logins and the db spends all its time reading disk.
-- before: full table scan
EXPLAIN SELECT * FROM users WHERE email = '[email protected]';
-- Seq Scan on users (cost=0.00..412,000.00 rows=1)
CREATE INDEX idx_users_email ON users(email);
-- after: index scan
-- Index Scan using idx_users_email (cost=0.43..8.45 rows=1)for compound queries, column order in the index matters. for WHERE status = ? AND created_at > ?, an index on (status, created_at) helps queries on status alone and queries on both — but won't help queries filtering only by created_at.
"millions of concurrent reads to the same key"
celebrity drops a post. millions try to read the same cached entry simultaneously. your cache server, which normally handles 50k qps, is suddenly looking at 500k qps for ONE key. it starts timing out. site goes down — purely from read traffic.
the problem is that traditional caching assumes load distributes across many keys. when everyone wants ONE key, the assumption breaks. even though the data is in memory, serializing it and sending it over the network 500k times per second melts the cache server.
fix 1: request coalescing. when multiple requests hit the same key on the same server, combine them into a single backend request. one fetch, broadcast the result.
class CoalescingCache:
def __init__(self):
self.inflight = {}
async def get(self, key):
if key in self.inflight:
return await self.inflight[key]
future = asyncio.Future()
self.inflight[key] = future
try:
value = await fetch_from_backend(key)
future.set_result(value)
return value
finally:
del self.inflight[key]caps backend load at N — the number of app servers. even if a billion users want the same key, the backend only sees one request per server.
fix 2: cache key fanout. spread one hot key across multiple entries. instead of feed:taylor-swift, store the same data under feed:taylor-swift:1 through :N. clients pick a random suffix. now those 500k qps distribute across N keys. trade-offs: more memory, more invalidation work. for hot-key scenarios that threaten availability, that redundancy is dirt cheap insurance.
✽ RECALL a celebrity post turns one cache key into 10× your cache server's capacity and the site dies from pure read traffic. why does the cache melt even though the data is in memory, and what are the two fixes?
caching assumes load spreads across many keys — when everyone wants ONE key, serializing and shipping the same value hundreds of thousands of times per second saturates the server regardless of where the data lives. fix one: request coalescing — duplicate in-flight requests on a server collapse into a single backend fetch, capping load at one request per app server. fix two: key fanout — store the value under N suffixed copies and let clients pick randomly, spreading the heat.
"cache stampede when hot entries expire"
your homepage data has a 1-hour TTL. serving 100k qps from cache like a champ. the hour ticks over. all 100k requests in that instant see a miss simultaneously. every single one tries to rebuild from the db. your db, sized for maybe 1k qps of misses on a normal day, is now staring at 100k identical queries. self-DDoS. cache stampede.
three approaches, in increasing sophistication:
- distributed lock — only the first miss rebuilds; everyone else waits. protects the backend, but if the rebuild fails or stalls, thousands of waiters time out. fragile.
- probabilistic early refresh — as the entry ages, each request has a small but growing chance of triggering a background refresh. 1% at minute 50, 5% at 55, 20% at 59. instead of stampeding at minute 60, refreshes spread across the last 10 minutes. clean, no locks.
- scheduled background refresh — a worker continuously refreshes the hottest entries before expiry. they never go stale. costs ops complexity and you waste work on entries that might not be requested, but for hot content it's worth it.
✽ RECALL a hot entry's TTL expires and your db gets self-DDoSed by identical rebuild queries. why does probabilistic early refresh beat a distributed lock here?
the stampede happens because every request sees the miss at the same instant. a lock lets only the first miss rebuild, but if that rebuild stalls or fails, thousands of waiters time out — fragile. probabilistic refresh gives each request a small, growing chance of triggering a background rebuild as the entry ages, so refreshes spread across the final minutes instead of detonating at expiry. no locks, no waiters, clean.
"users need updates immediately — eventual consistency isn't enough"
eventual consistency is fine for most stuff. user changes their bio? if it shows up in 30 seconds across all caches, who cares. but for some data, stale is unacceptable. event venue updates 30 minutes before kickoff? attendees can't be looking at the old address.
naive approach is to delete the cache on write. real problems: which caches do you delete from (Redis, CDN, browser)? what if delete fails? race condition — another request reads from a follower replica that hasn't replicated yet, gets the old value, writes it back to the cache after you deleted it. cache has stale data again.
better approach: cache versioning. instead of deleting old entries, you make them unreachable by changing the cache key whenever data changes. each record has a version column. every update increments it in the same transaction. on read, fetch the current version, build the cache key as entity:id:vN, fetch using that key. on write, bump the version (v42 → v43), write new data under the new key.
event:123:v42 # before update
event:123:v43 # after update — readers automatically move hereold entries never get explicitly deleted — they just become unreachable. let TTLs clean them up.
why this kills the race condition: a "late writer" can't overwrite new data because the db forced a new version number. their write lands at v42, nobody's reading v42 anymore. no partial-invalidation worries — you're not deleting anything, you're routing past it. atomic by definition because version increments are atomic in the db.
trade-offs are real: two cache lookups per request, small extra latency. old versioned keys accumulate so you've gotta TTL them. and this works best for single-entity caches like profiles or product details — doesn't help much with computed data like search results or feeds where invalidation is inherently complex.
for computed data, a deleted items cache is your friend. small working set of recently deleted/hidden/changed IDs. when serving feeds, filter cached results against this set. lets you serve mostly-correct cached data immediately while doing proper invalidation in the background.
✽ RECALL why does cache versioning kill the stale-write race that delete-on-write can't?
with delete-on-write, a reader can grab the old value from a lagging replica and write it back into the cache after your delete — stale data resurrected. with versioned keys, every update atomically bumps a version in the same db transaction, readers build keys from the current version, and the late writer lands on vN while everyone reads vN+1. nothing is deleted — you route past old entries and let TTLs sweep them up.
wrapping up
read scaling is the most common scaling challenge in production because read traffic grows exponentially faster than write traffic, and at scale physics wins. no amount of clever code can outrun hardware limits when you're serving millions of concurrent users.
the path is the same every time: optimize within the db first (indexes, composite/covering, denormalize if you must), scale horizontally if you've gotta (read replicas first, sharding only when the dataset is the bottleneck), cache the rest (Redis/Memcached at the app layer, CDN at the edge).
the most common mistake is skipping rungs. teams jump straight to "let's add Redis" without ever checking if a composite index would've solved it for free. don't be that team. start cheap, climb only as far as you need.
nothing is best. everything depends on your usecase, your read patterns, your consistency budget. you're paid to solve a problem, not to ship the fanciest architecture.