Scaling | DB Proxy Pattern
Scaling
When I ask people, "Hey what do you think is scaling?" They say, "Yeah we have to handle large number of requests. Large number of concurrent requests." Because when you have to handle a large number of concurrent requests, that's where the real challenges begin.
Two Classic Scaling Strategies
So again two classic strategies:
- Vertical scaling - scale up (add more CPU, RAM, disk)
- Horizontal scaling - scale out (add more machines)
I won't spend time over that. But what I would spend time over is on horizontal scaling - the best and the worst part of horizontal scaling is that it gives you something called as linear amplification.

Linear Amplification and Unit Tech Economics
People don't typically think about this much but something that you should certainly be thinking of - the core benefit of horizontal scaling is linear amplification. What does it mean? It implies that you can do unit tech economics.
You have seen Shark Tank where founders talk about unit economics:
- Customer acquisition cost vs customer lifetime value
- Scale business accordingly based on these numbers
Same thing for computers, softwares, infrastructures. Unit tech economics is about knowing the numbers:
- How many requests one machine can handle?
- How many requests one database can handle?
- For n requests, how many machines do I need?
This is unit tech economics and when you know your numbers you can then do linear amplification which essentially means that if you know beforehand the number of requests you would be getting or the amount of scale that you would need to handle, you can easily find out the number of machines you would need or the kind of infrastructure required.
There's No Magic Formula
So there is no magic formula that tells you number of requests that one machine can handle. You always have to do a load test to get the numbers. something fancy number fancy formula it doesn't work that way because what you are doing in each request is a huge factor.
For example when you get an API request:
- Is it CPU heavy stuff? Is it memory heavy stuff?
- If it's CPU heavy how heavy it is - encryption/decryption of small value or large value?
- If you're making database calls, how expensive is this query?
- Will this query execute in under 10 millisecond or will it take 50 millisecond?
- Are you buffering a lot of data in memory? Are you transferring a lot of data?
So you cannot come up with the number automagically and so there is no formula.
The best way: Write the code → Load test → Crunch numbers. That's your best bet, that's the most predictable bet, that's more informed - you are making an informed decision rather than guessing.
Again want to highlight this - there is no formula. Over time you can then make educated guesses about certain numbers but it's still not like it still can be way off. So the best way and the most effective and predictable way to do it is to run load tests and get numbers - hardly takes 10-15 minutes of your time but at least you would be completely certain.
The Catch with Horizontal Scaling
A lot of people think horizontal scaling is infinite scale but there's a catch - your stateful components should be able to handle those many requests.
Think about it: let's say you scale your API servers based on number of requests that are coming in and you have scaled the API servers but if your database is not able to handle the incoming load - then why on earth are you accepting the request? Because if you accept the request and most of your requests are hitting your database and your database cannot handle it, everything would suck up.
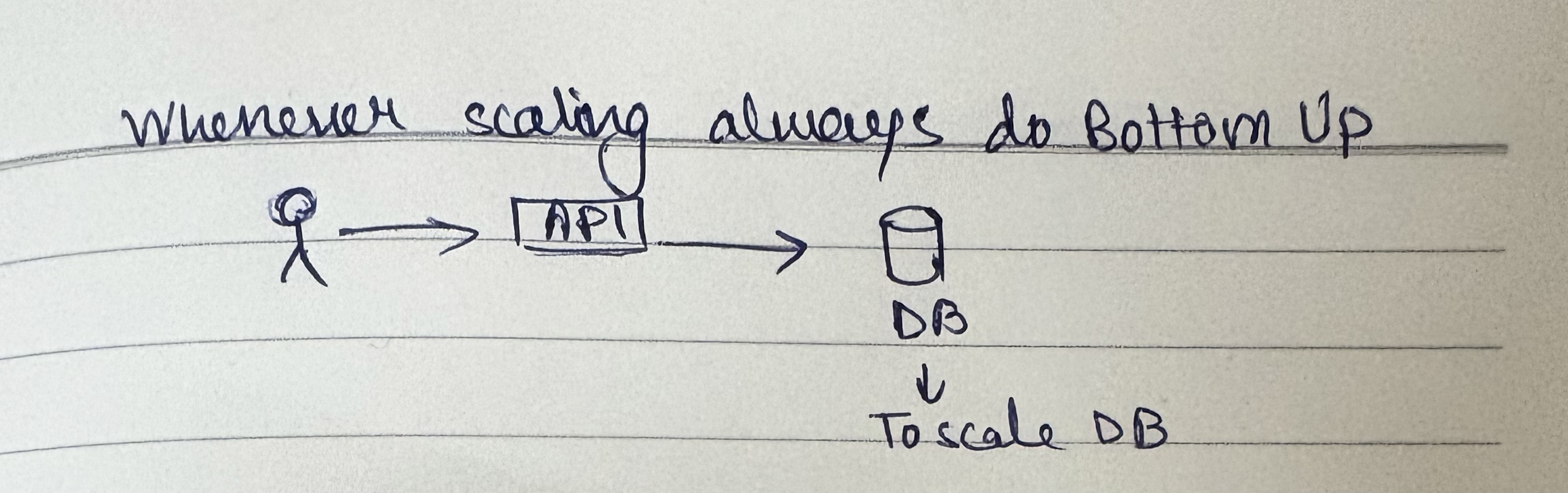
Bottom-Up Scaling
So a good way of scaling things is to do bottom up scaling. Typically people from Flipkart during their Big Billion Days or Amazon's five day sales - the scaling is almost always bottom up. You have to make sure that the services you depend on can scale - it could be an external third party service like a payment gateway integration like Razorpay or JusPay, it could be a database that you are depending on, it could be cache or Kafka or maybe some analytics tool - whatever services you are interfacing with, they have to scale.
Which is where IPL, the cricket league or new year's eve or sale events - these are actually the events where almost the entire good chunk of Indian startup ecosystem comes together because let's say Amazon is getting a lot of orders, of course the payment gateway has to scale, of course the banks have to be informed. So literally payment gateway works with banks to make sure that they are scaled. Everybody does forecasting - how many requests are we expecting? Everything is pre-planned, takes months to plan a mega event like this. Then you create playbooks which makes it a little easier, but the scaling when you're doing such big things is almost always bottom up.
Even if you're not doing big things, you're just configuring auto scaling group - when you get a request you still have to make sure that your underlying components scale. Typically database and other stateful components.
Stateful components are essentially some kind of state (may not be like just a customer but anything that has some kind of state management) because that makes it difficult. If your workload is stateless you can very easily scale it just like auto scale group because everything is stateless, they're not maintaining state so horizontal scaling becomes much easier. But the moment you have databases, cache, message brokers - that becomes relatively more complex.
Scaling Databases
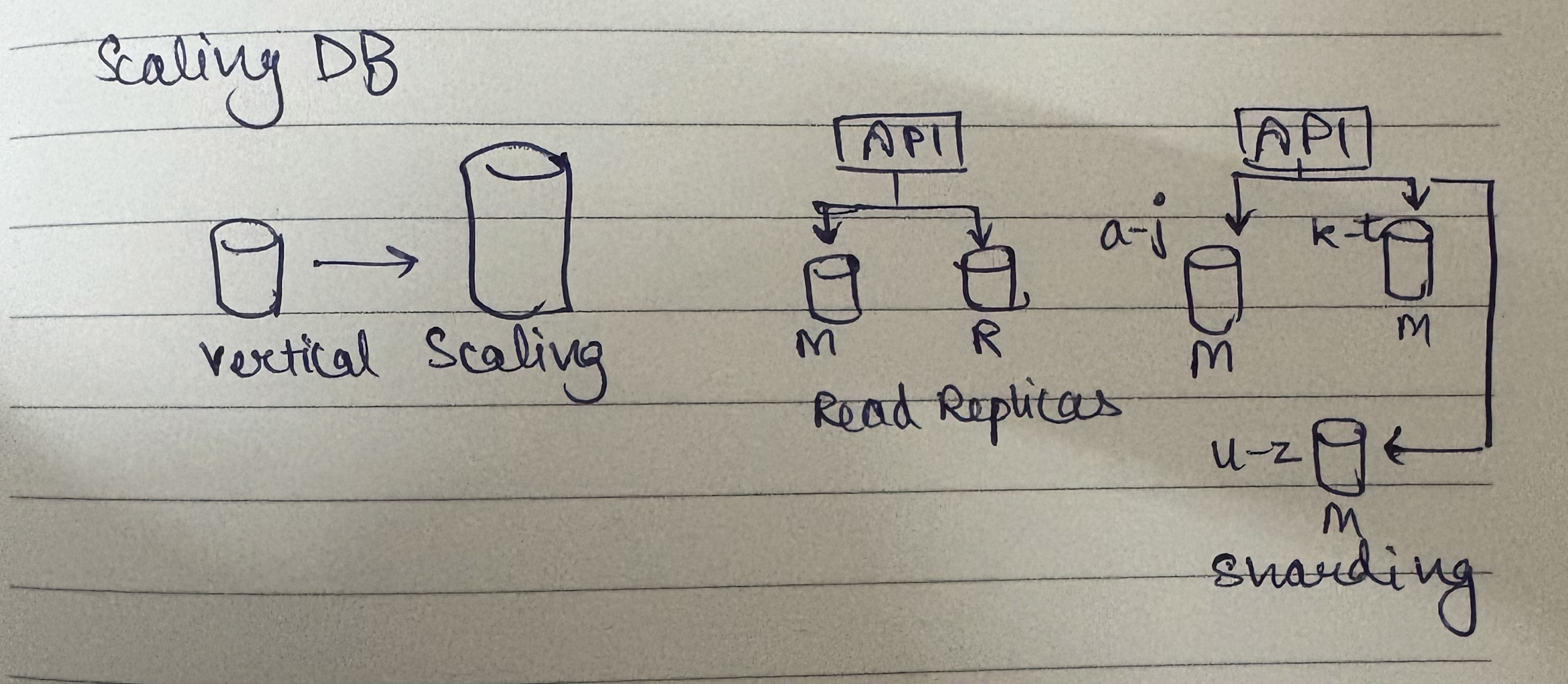
Now let's talk about scaling databases because that's where our discussion is going to segue. So scaling databases - you have three ways to do it:
Vertical Scaling
First of all vertical scaling - you need to handle more requests on the single machine, put in more CPU, more RAM, more disk and handle it. But when you do vertical scaling what typically happens is you almost always incur downtime even if it's for a shorter duration because that server needs to be shut down, size needs to be increased and then you have to bring it back up.
But in most cases this works just fine. For example Zerodha is still a single instance - you don't need fancy distributed database to solve your problem. If it works for you, it works for you. There is no one way to design a system so don't discard vertical scaling.
"Oh no vertical scaling has a limit" - are you hitting that limit? Is your startup of five people handling ten customers going to hit that vertical scale limit? No. Keep quiet and keep vertically scaling the system because you have to focus more on the business.
Remember this: Business → Product → Engineering. Engineering is always an enabler. If your business is not doing good, no matter how great your engineering, it doesn't matter. If your product is not doing well, no matter if you write good solid code, it does not matter.
So try to optimize for the shipping velocity while maintaining extensibility of your code and architecture. It's good that you're looking ahead in the future but a startup with five people and ten customers making hundred thousand dollars in revenue should not be thinking of ten years in the future. One year, maybe one and a half is a stretch.
You don't need to over-optimize. So if just clicking two buttons solves the problem - for example in the case of Zerodha, because after five o'clock trading doesn't happen, they have that breathing space. They can put database under maintenance. Banks do that every night - they put database under maintenance.
Key insight: Depending on the nature of your business, if you have an opportunity to relax your constraints - observe it, grab it with both hands and simplify your architecture. If it seems hacky but it works, so be it. You don't need to over-engineer everything.
Read Replicas
Second is where you think about "hey vertical scaling is good but I'm getting a large number of read requests, not enough write requests" - which is when read replicas come in. What you do is create a read replica out of the master. You typically configure it with async replication so replica periodically pulls the changes from the master (master does not push, replica pulls from master and applies the changes on its own copy of data).
Now here's the statement that everyone says: "Writes go to master and reads go to replica" - WRONG! That's an over-generalized statement, stay away from it. What this leads people to think is "my reads won't go to master" - untrue, completely untrue.
The real statement should be:
- Writes go to master
- Critical reads go to master
- Reads that are okay with staleness go to replica
Most reads are okay with staleness. For example on your banking website:
- Fetching profile information - even if it's stale, not end of the world
- But fetching account balance while transaction is happening should go to master - these are critical reads
So these generalized statements where people say "writes go to master and reads go to replica" is not completely correct. The correct thing is: writes go to master, critical reads go to master (consistent reads), and reads okay with staleness go to replica.
How to Configure Read/Write Split
The logic is very simple. Create your master and your replica as different databases - they are different databases, they just have the same copy of data. When you create your connections:
- Create connection with your master instance
- Create another connection with your replica instance
When you write code in Django or Java or whatever language you prefer, you do sql.connect or sql.open and pass the connection string:
- Pass connection string of master → that database connection object talks to master
- Pass string of replica → database now talks to replica
So on server boot up you create connections with both the databases. Now in your API handler you write the code:
- "Profile read" - ah it can go to replica, done. Use the replica connection object to fire the query
- If you know this read has to go to master, use the master connection object
It's up to you depending on the API - you either use master connection object or replica connection object. Simple.
Sharding
Now you have master and replica. Let's say you got more reads - you can create one more replica. So one master, multiple replicas. If reads increase, add one more replica. So one master, three replicas. Now, what we have done is you've solved your problem of scaling reads. Awesome!
But what if your write load is high? You reach a certain state where the one node that you have cannot handle all the writes. In that case, you shard your database.
Instead of 1 database, you create three masters. They are all individual except they do not share the data. They have mutually exclusive subsets of data. A simple strategy could be range-based - a-j goes to shard 1, k-t goes to shard 2, u-z goes to shard 3. Each master can have its own replica - nobody is denying it. This master can have its own replica, this master can have its own replica, and this master can have its own replica.
So now, your API server knows the topology and creates a connection with each of the three databases. Depending on the request that comes in, you know where to go to get the data and use that corresponding connection object to fire the query, get the response, and respond back to the user. Literally the same thing that you do in replica is what you do over here. So when your server starts, you create connections with the entire topology, and depending on the request that you get, you would make a call to server 1, or server 2, or server 3.
Important Note: Assume 0 cross shard queries when doing sharding - complex queries which require data from 2 different shards should be avoided.
Database Proxy Pattern
What we saw was API server knowing the topology but what if I don't want that? Which means API server NOT knowing the topology - API server connecting to a single instance and that instance knows the topology. This is your database proxy pattern where you see ProxySQL, pgbouncer are examples of this where your API server effectively connects to one server, fires regular requests. This server knows SQL like MySQL dialect or Postgres dialect, it connects to that and fires regular query and this server decides - "hey should I forward request here or should I forward request here?"
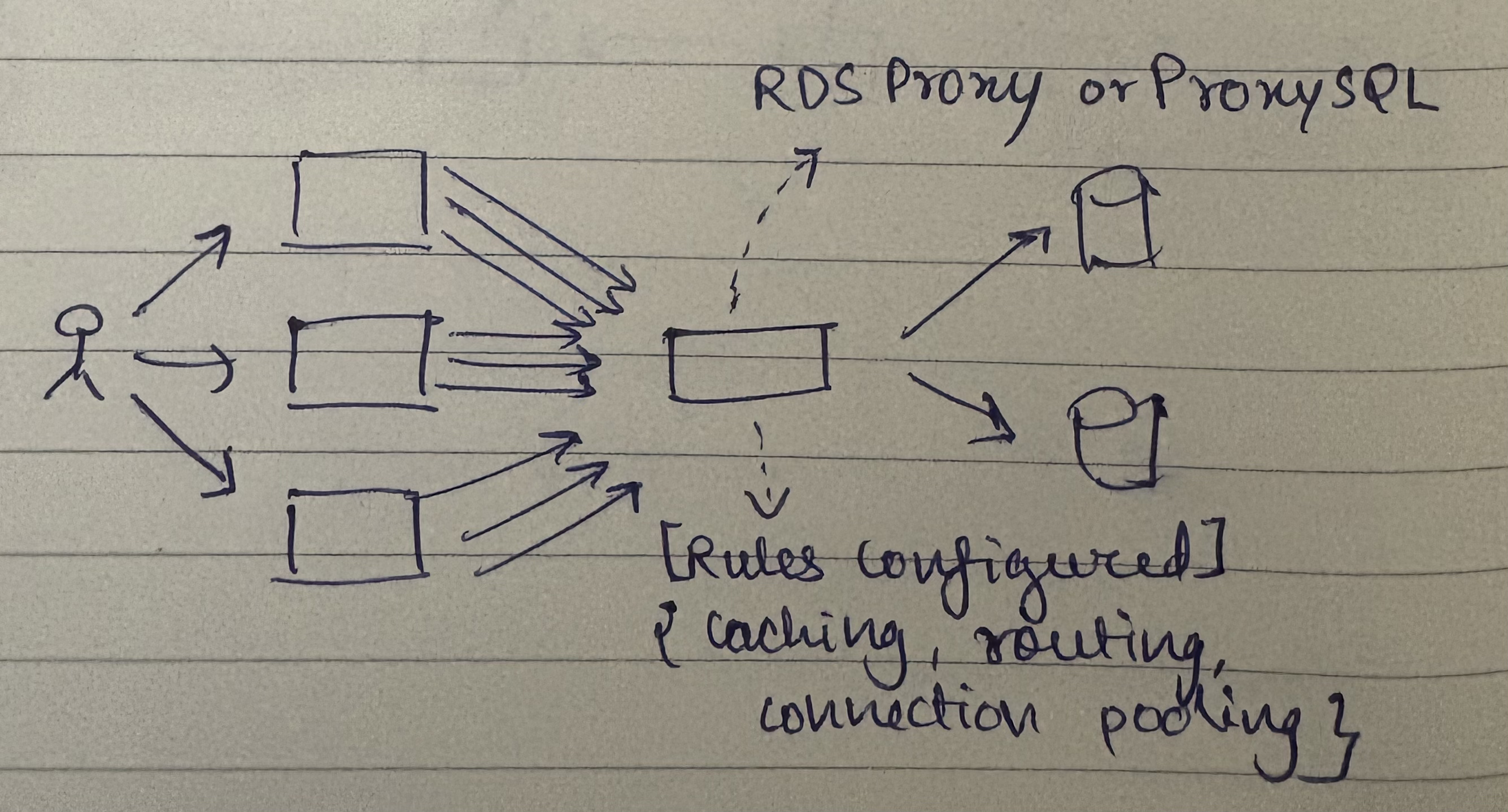
So framework of opposites again at play - either your API server knows the topology or the topology is abstracted from your API server which means API server connects to this proxy instance.
ProxySQL Configuration
Let's dig a little deeper into ProxySQL. The thing is, ProxySQL instance that you have is also a database because it understands SQL dialect. So what you do is when you start your ProxySQL (it is a MySQL proxy), you can configure rules. You configure your database topology - for example this is literally what you would run on a ProxySQL:
INSERT INTO mysql_servers (hostgroup_id, hostname, port)
VALUES (10, 'db-master.example.com', 3306),
(20, 'replica1.example.com', 3306),
(20, 'replica2.example.com', 3306);
LOAD MYSQL SERVERS;
SAVE MYSQL SERVERS;
You can provide host group id, hostname and port - essentially you are defining your database topology and they call it host groups. Simple - I create two host groups, one is primary, one is replica. So this is what we have configured - this is my current database topology.
Now you can also add multiple replicas. Think of host group as a logical grouping of databases - when a request comes to this host group, then the request will be redirected to a server in that host group. So if your host group contains master, the request will go to master. If the host group contains multiple replicas, then it will do round robin or whatever algorithm you can choose.
Query Routing Rules
When you fire the request to ProxySQL instance, it picks - let's say you're routing it to a particular host group and that host group contains three servers - to which server would it send the request to? It sends a request based on least connection based routing - the server to which it has created the least number of connections, it sends there so that the request can be fulfilled faster.
Now when you fire the query - I want all of my selects to go to replica, all of my selects. So what you configure is something called as a match pattern (essentially regex). What ProxySQL does is a simple regex match of all the rules that you configured:
INSERT INTO mysql_query_rules (rule_id, active, match_pattern, destination_hostgroup)
VALUES (1, 1, '^SELECT.*', 20);
LOAD MYSQL QUERY RULES;
SAVE MYSQL QUERY RULES;
You provide matching patterns and you say that if this pattern is matched, do what. So you provide a destination host group. So if my query starts with SELECT, send it to destination host group 20 (20 is my replica host group).
Advanced Routing Configurations
Let's say you have another use case where you have two master instances. Let's say analytics DB and some transaction DB. And what you want is that requests going to a particular schema should go to different host groups. You can configure rules like this:
-- Route analytics queries to hostgroup 1
INSERT INTO mysql_query_rules (rule_id, active, schemaname, destination_hostgroup)
VALUES (1, 1, 'analytics_db', 1);
-- Route transaction queries to hostgroup 2
INSERT INTO mysql_query_rules (rule_id, active, schemaname, destination_hostgroup)
VALUES (2, 1, 'transaction_db', 2);
You can also pass hints in your SQL query that you are constructing - you can forcefully say send it to host group 1 or send it to host group 2:
SELECT /*+ PROXYSQL_HOSTGROUP=1 */ * FROM users WHERE user_id = 1234;
So no matter which database the request was originally going to, you have overwritten and said that fire this request to host group 1. So when this request comes to ProxySQL, it will forward it to host group 1 irrespective of other rules because you asked it to explicitly be fired on host group 1.
Comment-Based Routing
This is essentially called host group hint but that's not ideal because you have to know the host group ids which means your ProxySQL logic gets percolated in your business logic - not a good sign. But you can still work with this.
What you can also do is comment based routing. I can say if there is a comment in my SQL query which says /*read*/ send it to replica 20. If it says /*write*/ send it to host group 10:
-- Configure comment-based routing rules
INSERT INTO mysql_query_rules (rule_id, active, match_pattern, destination_hostgroup)
VALUES (1, 1, '/*read*/', 20),
(2, 1, '/*write*/', 10);
You can change it to anything - literally change into any string and then it's a regular expression match. So then when you create your query you can actually add a comment to your query:
SELECT /*read*/ * FROM users WHERE user_id = 1234;
So now you control in your business logic where to send the request to without knowing hostgroup numbers. You can route depending on the query rule you configure.
This way I can send /*read*/ on my stale selects because it can go to replica. What I can also do is if it's a critical read I can still do /*write*/ - it's not a write query but it's just a string that you are matching. So then that select will go to master because ProxySQL will match and say "it's write" and send to host group 10.
Scaling ProxySQL
The key thing is the elasticity of your infrastructure is not affecting your API servers - your API servers don't know what the infrastructure topology is, what your database topology is. ProxySQL is taking care of redirection. Yes you add a network hop - that's ok, not the end of the world because all it is doing is matching and relaying so this network hop is not costly. The benefit you get by doing this is way more in most cases than the additional network hop that you are putting in. 3-4 millisecond additional jump, not the end of the world.
How do we scale ProxySQL? Classic vertical scaling - add more resources because all it is doing is matching and relaying so you can easily vertically scale this instance and it would work just fine. But if you want to scale this horizontally then what you have to do is put a load balancer before this and let your API server talk to this load balancer - this could be an L4 load balancer.
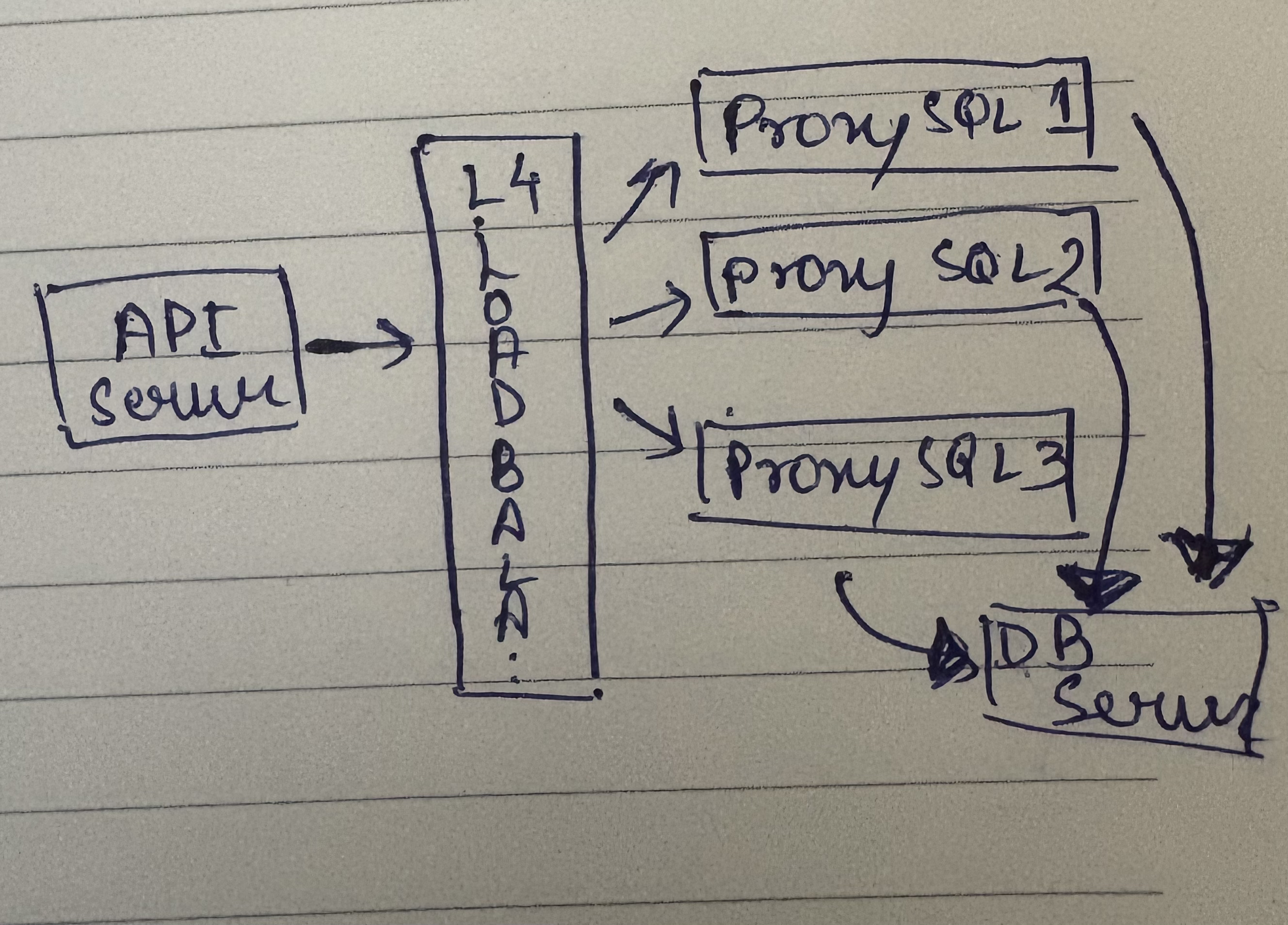
API server talks to this load balancer, load balancer forwards the request to any of the ProxySQL instances. So each of the ProxySQL instances should have the same set of routing rules - the rules will be configured in each one of them individually and you put a load balancer in front of it. So when your request comes from your API server to the load balancer, it forwards to a ProxySQL instance and depending on the routing rule it sends to the appropriate database.