remote locks and distributed locks
where do remote locks even fit in?
before we jump into remote locks and distributed locks, lets take a step back and understand where they fit in. there's a beautiful logical evolution here that most people miss.
when you have multiple threads that need to synchronize, you use a mutex or a semaphore. why? because threads share the same memory space, so an in-memory primitive is the closest possible synchronization mechanism. dead simple.
now bump it up a level. when you have multiple processes on the same machine that need to synchronize, you use the disk. why? because disk is the shared common storage between processes. a beautiful real-world example of this is apt-get upgrade. try opening two terminals and running apt-get upgrade on both simultaneously. the second one will throw an error saying dpkg.lock file exists. the process creates a lock file on disk when it starts, and if another instance sees that file, it kills itself. two processes synchronizing through disk.
now bump it up one more level. when you have multiple machines that need to synchronize, what's the closest shared resource? the network. and that's exactly where remote locks come in.
┌──────────────────────────────────────────────────────────────┐
│ synchronization evolution │
├──────────────┬──────────────────┬────────────────────────────┤
│ scope │ shared resource │ mechanism │
├──────────────┼──────────────────┼────────────────────────────┤
│ threads │ memory │ mutex / semaphore │
│ processes │ disk │ lock files (dpkg.lock) │
│ machines │ network │ remote locks │
└──────────────┴──────────────────┴────────────────────────────┘
you try to synchronize with the closest possible shared storage available. that's the pattern.
what are remote locks?
remote locks are essentially locks managed by a central machine — we call it the lock manager. it's a central component that multiple machines coordinate through.
┌─────────────────┐
│ Lock Manager │
│ (Redis) │
└───────┬─────────┘
╱ │ ╲
╱ │ ╲
┌────────────┐ ┌────────────┐ ┌────────────┐
│ Machine 1 │ │ Machine 2 │ │ Machine 3 │
└────────────┘ └────────────┘ └────────────┘
the 3 machines coordinate through a central lock manager. simple enough right?
lets build some intuition with a stupid queue
to understand remote locks better, let's set up a problem. imagine you have a message broker — a remote queue. but this queue is stupid. it gives you no guarantees whatsoever. it's not SQS, it's not kafka, it's nothing fancy. it's a mythical, stupid, unprotected queue.
queue (q7)
┌──────────────────────────────────────────┐
───>│ □ □ □ □ □ □ □ □ │────┐
└──────────────────────────────────────────┘ │
│
┌───────────────────────────────┘
│
┌─────────┼───────┬───────────────┐
│ │ │ │
┌─────┴──┐ ┌────┴───┐ ┌─┴────────┐ ┌───┴───┐
│Consumer│ │Consumer│ │Consumer │ │ Redis │
│ 1 │ │ 2 │ │ 3 │ │ (Lock │
└────────┘ └────────┘ └──────────┘ │Manager│
│ │ │ └───────┘
└────────┼────────┘
│
all consumers
coordinate via redis
what we want is that when one consumer reads from the queue, the other two should wait. once the first one is done, the next one gets a turn. that's it. we want multiple machines to coordinate so that only one accesses the queue at a time.
the consumer's pseudocode
at a high level, every consumer runs this loop:
ACQ_LOCK() ← acquire the lock
READ_MSG() ← read, process, and delete the message
REL_LOCK() ← release the lock
all consumers wait on ACQ_LOCK() while one of them does READ_MSG(). once the active consumer releases the lock, the next one gets in. then the third one. and so on.
what do we need from the lock manager?
two core properties:
atomic operations — so that two machines don't acquire the lock simultaneously. when one consumer is setting the lock, no other consumer should be able to sneak in. no race conditions.
automatic expiration (TTL) — imagine consumer 1 acquires the lock, starts processing, and then dies mid-way. if there's no expiration, that lock is held forever. nobody can make progress. so we need a timeout that auto-releases the lock after some time in case there's no graceful deletion.
so which database gives us both atomicity and TTL? redis. it's the popular choice because it's in-memory, which means it's fast. dynamodb works too, but redis is what most people reach for.
implementation with redis
the idea is straightforward. you set a key in redis that says which consumer holds the lock. the key is the queue id, and the value is the consumer id.
eg: q7 : consumer2 [ex: 300]
↑ ↑
lock held by expiration: 5 min
consumer 2
the magic here is SET NX — set if not exists. if the key already exists, it means some other consumer holds the lock, and the command returns 0. if it doesn't exist, the key is set and it returns 1. each command in redis is atomic, so no two consumers can race past this.
acquire lock
def acquire_lock(q):
consumer_id = get_my_id()
while True:
v = redis.setnx(q, consumer_id)
if v == 1:
redis.expire(q, 300) # TTL of 5 minutes
return
else:
continue # busy wait
yep, it's busy waiting. not the most elegant, but it works. each consumer keeps trying setnx in a loop. the moment it succeeds (returns 1), it sets the TTL and returns from the function. otherwise, it keeps spinning.
release lock
your first instinct might be to just delete the key:
def release_lock(q):
redis.delete(q)
but think about this. consumer 1 acquires the lock, starts processing, and takes longer than expected. the TTL expires. the lock auto-releases. consumer 2 now acquires the lock and starts processing. consumer 1 finishes its work and calls release_lock — and blindly deletes the key. but that key now belongs to consumer 2. consumer 1 just deleted someone else's lock. now consumer 3 can waltz in and you've got two consumers processing simultaneously. chaos.
that's why we verify ownership before deleting:
def release_lock(q):
consumer_id = get_my_id()
v = redis.get(q)
if v == consumer_id:
redis.delete(q)
if the value in redis doesn't match my consumer id, i don't touch it. it's not my lock to release.
but there's one more subtlety here. the get and delete are two separate commands. what if between the get (which returns my consumer id) and the delete, the TTL expires, another consumer acquires the lock, and then my delete fires? same problem again. these two operations need to be atomic. in redis, you achieve this using EVAL — executing a lua script atomically on the server.
redis.eval("if get(q) == c : del(q)")
the lua script runs atomically on the redis server. no interleaving between the check and the delete. no race condition. clean.
where else do we see remote locks?
this pattern is everywhere in distributed systems. mongodb transactions, for example, use remote locks on the involved rows. when you run a multi-document transaction in mongodb, it acquires locks on the documents involved so that no other transaction can modify them concurrently. the mongos router coordinates these locks across shards — essentially the same remote locking pattern we just built. one central coordinator making sure multiple machines don't step on each other's toes. if you want to dig deeper into how mongodb handles this internally, their official docs on transactions and the wiredtiger storage engine's locking model are solid reads.
but there's a problem. what happens if your single redis node goes down? nobody can acquire the lock. you've got a single point of failure. and that's exactly why distributed locks exist.
distributed locks — redlock
the idea behind distributed locks is simple: what we did with a remote lock on one node, just distribute it across multiple nodes.
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ A │ │ B │ │ C │ │ D │ │ E │
│ 1 │ │ 2 │ │ 1 │ │ ✗ │ │ 1 │
└─────┘ └─────┘ └─────┘ └─────┘ └─────┘
5 master nodes of redis. no replication. all independent.
you have 5 independent redis master nodes. no replication between them. all standalone. the concept is that instead of acquiring a lock on one node, you acquire a lock on the majority of these nodes.
acquire lock (distributed)
REDIS_SERVERS = [., ., ., ., .]
QUORUM_COUNT = ceil(len(REDIS_SERVERS) / 2) # 3 out of 5
def acq_lock():
count_acq = 0
for i in random.shuffle(range(5)): # random order
count_acq += redis[i].setnx(q, c, ex=300)
if count_acq >= QUORUM_COUNT:
return # got the lock!
else:
# release locks on nodes where we did acquire
for i in range(5):
redis[i].eval("if get(q) == c : del(q)")
the client goes through all 5 nodes, trying to SET NX on each. if it acquires the lock on the majority (3 out of 5), it's done — lock acquired. if not, it releases whatever locks it did acquire and tries again.
that last part is crucial. if you don't release the partial locks, you get deadlocks. imagine consumer 1 gets a lock on nodes A and B, consumer 2 gets C and D, consumer 3 gets E. nobody has the majority. so everybody releases and retries. on the next round, maybe consumer 2 gets A, B, and C — majority acquired.
release lock (distributed)
same lua script as before, but fired at all 5 nodes:
for i in range(5):
redis[i].eval("if get(q) == c : del(q)")
fault tolerance — the whole point
so why did we go through all this trouble? because with distributed locking, we no longer have a single point of failure.
lets say consumer 2 holds the lock on nodes A, B, and C. if node D goes down, no problem — 2 still holds the majority. if node E also goes down, still no problem — 2 has 3 out of 3 remaining, but more importantly, 2 already holds 3 out of the original 5.
with 5 nodes, you can survive 2 node failures.
the quorum count trap
here's where people get confused. lets say nodes C and D go down. you think "well, 3 nodes remain, so the quorum should be 2 out of 3 now, right?"
hell naw.
look at the code again:
REDIS_SERVERS = [., ., ., ., .]
QUORUM_COUNT = ceil(len(REDIS_SERVERS) / 2) # 3
REDIS_SERVERS is a static configuration. it's a hardcoded list that every consumer has when it starts up. it doesn't dynamically shrink when a node becomes unreachable. a node going down doesn't mean it gracefully removes itself from everyone's config — it just stops responding. the list still has 5 entries. len(REDIS_SERVERS) is still 5. QUORUM_COUNT is still 3.
and honestly, you wouldn't want it to change. think about why. the whole point of quorum is that any two majorities must overlap on at least one node. if you have 5 nodes and need 3, any two groups of 3 will share at least 1 node — which prevents two consumers from both thinking they own the lock. the moment you start shrinking the quorum dynamically ("oh only 3 nodes are alive, so 2 is enough"), you break that overlap guarantee. consumer 1 could get nodes A and B, consumer 2 could get node E, and both think they have majority of the "alive" set. that defeats the entire purpose.
so the quorum is fixed at 3 out of 5. if 2 nodes are down, you need all 3 remaining nodes to agree. that's harder, sure. but that's the price of correctness. and if 3 nodes go down? well, majority is mathematically impossible with only 2 nodes, so the system halts. no lock can be acquired. that's a feature, not a bug — better to stop than to hand out locks incorrectly.
the tradeoff spectrum
here's where it gets interesting. there are three architectures, three different trade-off profiles. think of it like convincing friends to go to a restaurant.
┌──────────────────────┐ ┌──────────────────────┐ ┌─────────────────────┐
│ Remote Lock │ │ Remote Lock + Replica│ │ Distributed Lock │
│ (Single Node) │ │ (Master-Replica) │ │ (Redlock) │
│ │ │ │ │ │
│ ↑ throughput │ │ ↑ throughput │ │ ↓ throughput │
│ ↑ correctness │ │ ↓ correctness │ │ ↑ correctness │
│ ↓ availability │ │ ↑ availability │ │ ↑ availability │
│ │ │ │ │ │
│ convince 1 friend │ │ 1 friend + backup │ │ convince 3 of 5 │
└──────────────────────┘ └──────────────────────┘ └─────────────────────┘
remote lock (single node) — very high throughput because you only need to convince one friend to go to the restaurant. very high correctness because there's one source of truth. but if that node dies, game over. availability is gone.
remote lock with replica — you get throughput (just write to master) and you get availability (if master dies, replica takes over). but correctness takes a hit. imagine you acquire a lock on the master, and before it propagates to the replica via async replication, the master dies. the replica never got the lock entry. now two consumers think they own the lock. bad.
distributed lock (redlock) — you get high correctness because majority consensus means even if a node goes down, the lock state is safe. you get high availability for the same reason. but throughput suffers because now you're convincing 3 out of 5 friends to agree on a restaurant. consensus always slows things down.
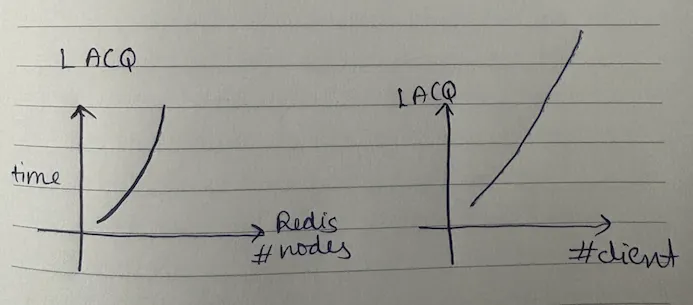
as the number of redis nodes increases, your lock acquisition time goes up. and as the number of clients (consumers) contending for the lock increases, it gets even slower. exponentially slower.
when do you use what?
there's no one right answer. it depends on context.
remote lock (single node) — most people use this. high throughput, simple setup, and they're okay with the availability risk. classic use case: consumer synchronization where lock contention is frequent and you need fast acquisition.
distributed lock (redlock) — this exists for situations where availability is absolutely critical. think database leader election. it doesn't happen frequently, but when it does, you cannot tolerate failures. if you give up on correctness during leader election, you get data inconsistency, data corruption — huge problems. so you're willing to pay the latency cost for the guarantee.
remote lock with replica — right in the middle. a little VC money, a little correctness, a little availability. sometimes good enough.
nothing is best. everything depends upon the usecase and the constraints you're operating under. you pick one over another based on what trade-offs you're willing to make. you are paid to solve a problem and not necessarily use the fanciest architecture to solve it.