load balancer
load balancer is like salt. we assume they're there - by default.
but load balancer is one of the most crucial things out there because load balancers make scaling easy. they abstract out the elasticity of the infrastructure. for example, because of this load balancer, you don't care how many api servers are behind this. you simply don't care. you add more nodes, you remove nodes, it doesn't matter. the users don't need to know.
again, framework of opposites: either user knows the topology or user does not know the topology. in this case, of course users don't need to know how many servers are running behind the scenes. they don't, because they're like "hey, i want to publish this tweet" - post, done.
so load balancer essentially abstracts out the topology behind it.
now load balancers help you achieve two things:
- fault tolerance (which means even if one of the servers is not available, your request can be routed to any other available server)
- no overloaded servers (because the load is balanced).
absorb the patterns to achieve high availability.
design requirements
when designing a load balancer, we need to
- balance the load (distribute requests evenly)
- have a tunable algorithm (support different distribution strategies)
- scale beyond one machine (handle growth).
setting up the foundation: terminology
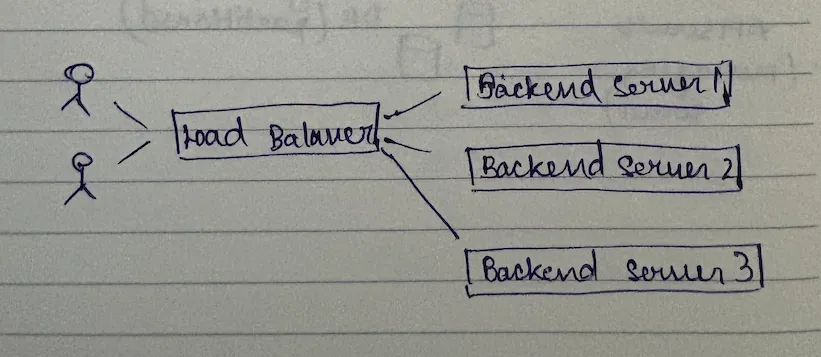
before we go into brainstorming, let me lay the foundation. we'll be having two types of servers in the system: backend servers (all service, payment service, purposes - what could be behind the load balancer, like what you are load balancing against) and lb servers (actually the load balancer, because load balance is also a process that is running, it's a server that is handling those).
so you have your clients, there are lb servers, and multiple lb servers constitute load balancer. so: client → lb server → backend server.
the classic load balancer implementation works like this: your lb server is the first point of contact. when the request comes in, it gets a request and then what it would do is - given this request, it would figure out which of the three backend servers should it forward the request to.
this is what its job is.
- get the request
- find the backend server
- forward the request
- get response
- send response to user
the configuration challenge
so with getting the request, of course we don't have to do anything - load balancer got the request because you made a request to that machine. pretty straightforward, http request came to the load balancer.
now what is load balancer doing when it got a request? it has to find the backend server. now for it to find the backend server, it needs to know the backend servers that are behind it. of course we need a database to hold this information. so let's call it simple Config Db.
what configuration do we need?
we need the balancing algorithm (round robin, weighted, hash-based, etc.), backend server list (which servers to route to), health endpoint (how to check if servers are alive), and poll frequency (how often to check health).
{
"load_balancer_1": {
"backend_servers": [
"backend_server_1",
"backend_server_2",
"backend_server_3"
],
"health_endpoint": "/health",
"poll_frequency": 5000,
"algorithm": "round_robin"
}
}
configuration db will store config per load balancer. a simple kv would work.
but here's the catch - making a db call upon getting every request will be catastrophic to the response times. if your lb server is serving millions of requests, that's millions of db lookups. not acceptable.
hence we keep a copy of the configuration in-memory of the lb server.
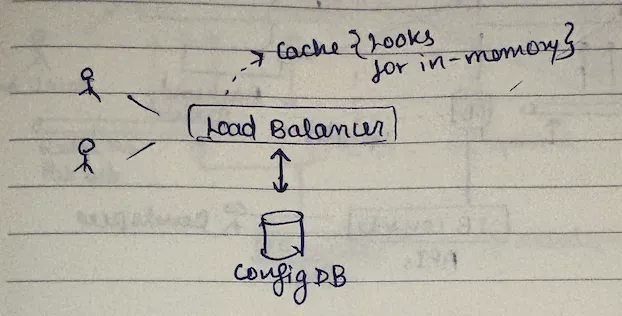
now as soon as you created a cached entry here, it introduces another problem: how do we keep these two in sync? because when someone changes the config in the db, how would it be reflected in the lb's cache?
push vs pull: the configuration sync pattern
this is your aws customer, this is your lb console which is a ui, it's a front-end package that you see all combined in one. it makes a call here, it updates the database. "i want to put this machine behind the load balancer. i want to add this machine behind this load balancer."
so as soon as config changes, what are you seeing? you have options.
option 1: push-based updates
the lb console pings the lb server saying "ok, there's an updated config, update your cache," and then the lb fetches from the db.
problems with pure push? well, if there are multiple lb servers, the lb console needs to know ip addresses of all of them. these lb servers can come up and down at their own sweet time - lot of metadata management. what if some servers are not responding? how long would you wait? if you're constantly bringing up new machines, it will create a lot of lag.
option 2: pull-based updates
lb servers poll the db periodically. super simple. no problem whatsoever. you don't have to worry about pushing and them acknowledging. poll frequency? say 30 seconds or a minute.
problems with pure pull? the time from when the update happens to when the lbs get updated - there will be up to 30 second lag. if you don't have jitter, all your lbs would end up calling the db at the same time. not acceptable when you're scaling rapidly and need immediate updates.
option 3: the hybrid approach (best of both worlds)
you could do something like a queue - pub/sub. redis or kafka? redis, not kafka. kafka is overkill for this use case.
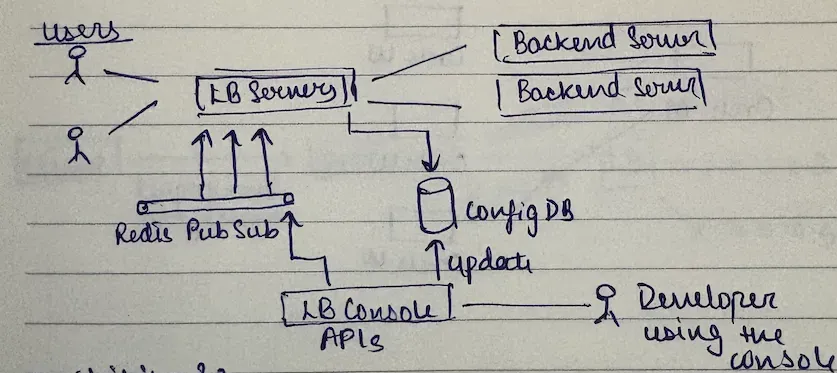
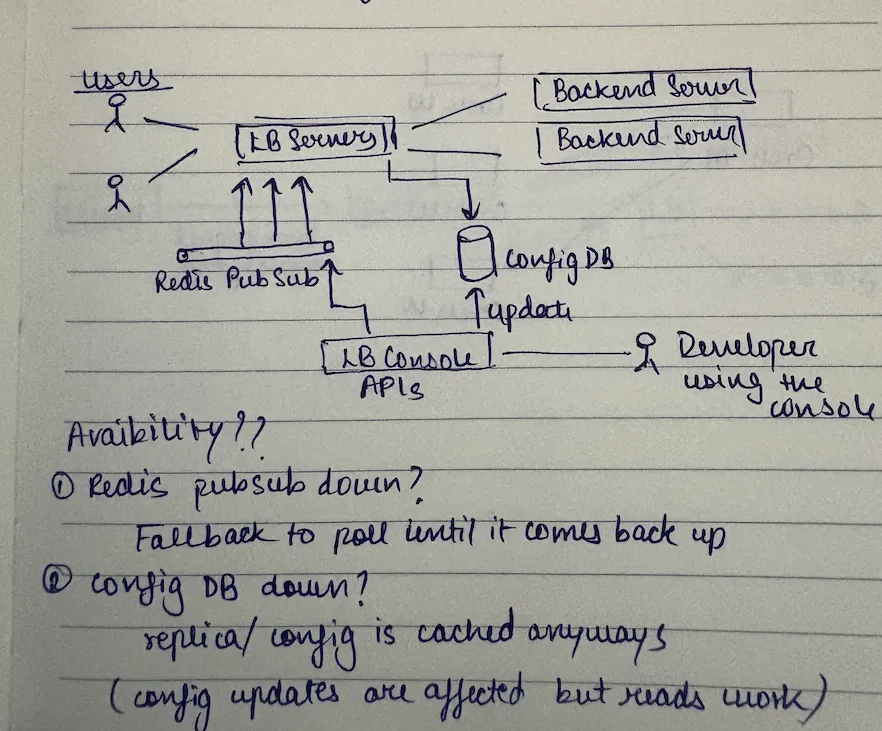
how it works? lb console updates the database, lb console pushes an event to redis pub/sub, lb servers subscribed to redis receive notification immediately, lb servers refresh their cache from db, and as a fallback, lb servers also poll every 30 seconds.
why this is brilliant? best case: instantaneous updates via push. worst case: 30-second delay if redis is down. high availability: system works even if redis fails.
so now this becomes highly available. now even if we added this component, our system is still highly available and still functional irrespective of when anything goes down.
the core ideology behind high availability is to have little redundancy. you have to have a plan b for a plan b for a plan b. that sort of stuff. so if this goes down, what's your plan b? if that goes down, what's your plan b? so always thinking of a fallback for a fallback for a fallback is the secret sauce.
health checks: knowing when servers are down
now what if a backend server goes down? what do you as a load balancer do? you need to first know that it went offline. heartbeat - so you need to first know that it's non-responsive.
three approaches to health checks
approach 1: lb server does health check
pros? simple to implement - just have a scheduled thread doing the polling. cons? if you have 5 lb servers, each backend gets pinged 5 times as often. your access logs would show /health /health /health getting called multiple times. this doesn't happen in real world.
approach 2: backend server pushes heartbeat
why this is bad? poor user experience. you're forcing customers to implement heartbeat logic just to use your load balancer. imagine aws telling you "to use our load balancer, modify your app to send heartbeats to these ips." absurd!
approach 3: separate component (orchestrator) ✓
this is what actually happens. a separate component handles all health checks.
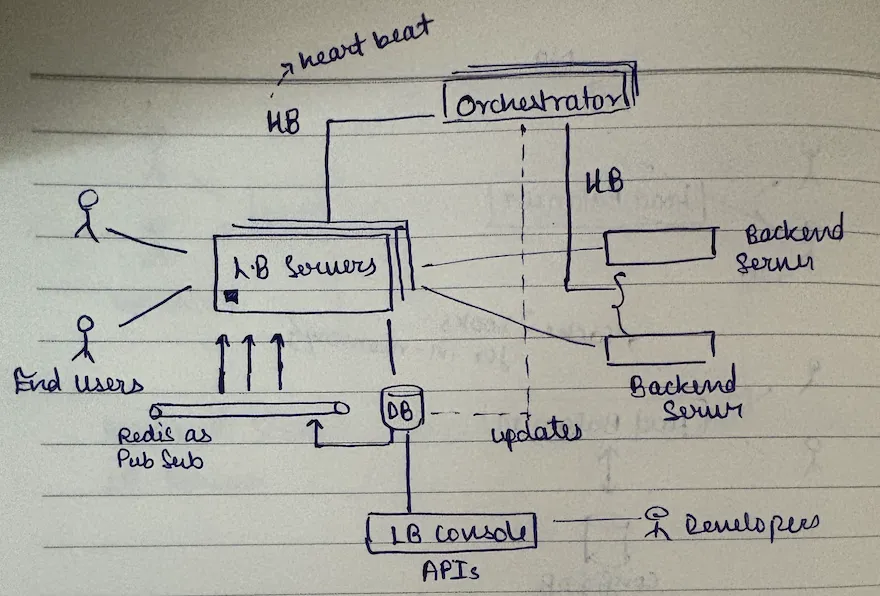
the orchestrator pattern
orchestrator responsibilities
the orchestrator keeps an eye on backend servers (health monitoring), updates the db if any backend server is unhealthy by removing it from the list (configuration updates), and monitors health of lb servers & scales them up/down (lb server monitoring).
but wait - what about high availability of the orchestrator itself? if orchestrator goes down, who monitors it? do we need a monitor for the monitor? and then a monitor for that monitor?
when you see this recursive pattern, that's when you need leader election.
leader election: breaking the recursion
this is the point where leader election takes place. leader election is the end of recursion. when you are in a place where you have to think of a load balancer for a load balancer, or monitor for a monitor for monitor - that's your indication to use leader election because it makes things self-healing.
the manager-worker pattern
real world analogy - think of your workplace.
the orchestrator master (manager) monitors workers health, assigns mutually exclusive work to workers, and redistributes work if a worker is down. the orchestrator workers (employees) do the grunt work, perform health checks, and update configurations.
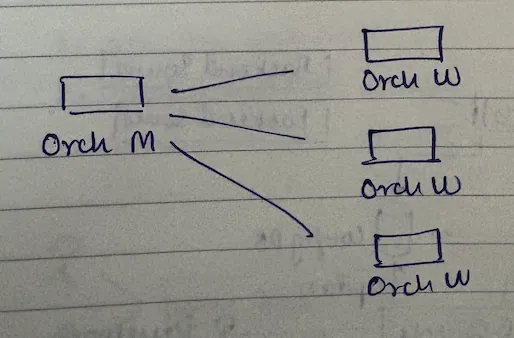
what happens when the manager (master) is absent? the senior-most person (or first to detect) becomes the temporary manager. that's leader election - bully algorithm, ring algorithm, whatever you want to use.
your system becomes self-healing. we live and breathe this every day.
this approach solves two problems: no standby nodes (every machine is doing useful work - no wasted money) and shared infrastructure (this orchestrator cluster can manage multiple load balancers).
monitoring and auto-scaling
how will the orchestrator decide when to scale lb servers? it needs metrics: cpu, memory, tcp connections.
enter prometheus:
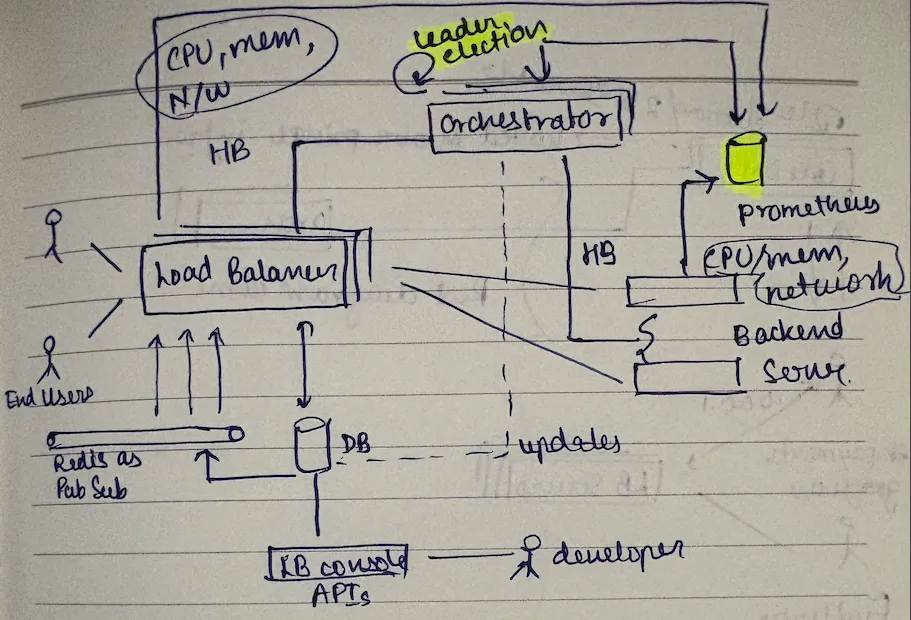
the orchestrator queries prometheus for metrics, decides if scaling is needed, and updates the configuration. we can also show these metrics to customers through the lb console.
scaling load balancers: the dns solution
now the only thing that remains is - lb servers cannot be just one instance. so how do we scale? what is that one thing that's shared and scales well? dns.
when you have multiple lb servers, how would customers know which ip to connect to? you give your load balancer a domain name:
lb.payment.google.com → [10.0.0.1, 10.0.0.2, 10.0.0.3]

that's why when you spin up a load balancer on aws, gcp, they give you a domain name. they're doing dns-based load balancing.
dns server properties? very lightweight (just returns ips for domain names), can handle 32,000 requests/second on a 4gb machine, heavily cached at multiple layers, and can balance resolution based on weights.

we might do round robin.
the question that i have in here: why return multiple real ips from dns? why not use virtual ips for the load balancers too, just like we did for dns servers?
so there can be various implementation. simple approach: dns → multiple real lb ips → backend servers. production approach: dns → virtual ips (each floating between multiple lbs) → backend servers. advanced approach: dns → single anycast ip (advertised globally) → backend servers (i will write about anycast in later blog).
so there can be various implementation
- simple approach: DNS → Multiple real LB IPs → Backend servers
- production approach: DNS → Virtual IPs (each floating between multiple LBs) → Backend servers
- advanced approach: DNS → Single Anycast IP (advertised globally) → Backend servers ( I will write about anycast in later blog) best part is client dosent need to know what are we doing actually
making dns highly available
we added dns - but what about its availability? if you're aws, you need this to never go down.
the virtual ip solution
two dns servers sharing the same virtual ip address: primary core dns (active) and secondary core dns (passive backup).
when secondary detects primary is down, it "takes over" the virtual ip. clients don't need to change configuration because the virtual ip remains the same.
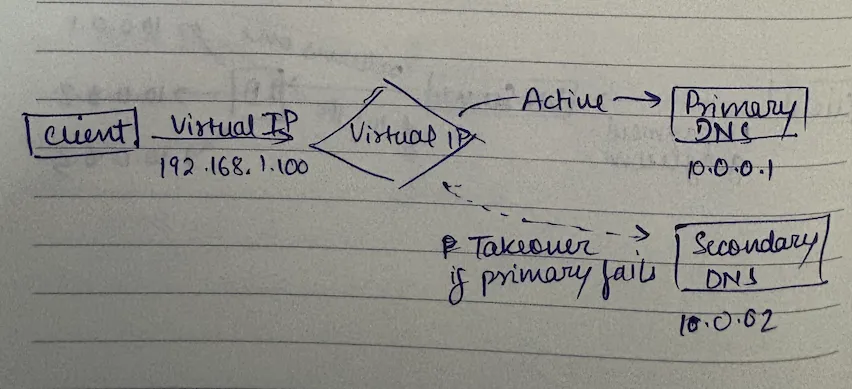
this uses vrrp (virtual router redundancy protocol):
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1234
}
virtual_ipaddress {
192.168.1.100
}
}
the secondary constantly monitors the primary. if primary fails, secondary starts advertising the virtual ip. this is configured at router/firewall level.
three types of load balancing
here's your buffet - three flavors of load balancing.
1. dns-based load balancing
how it works? lb.payment.google.com → [IP1, IP2, IP3, ...]
pros? easy, simple, flexible. supports various strategies (round-robin, geo-routing, weighted). great for initial distribution. cons? changes take time due to heavy caching across layers. no real-time load awareness. dns just returns ips, doesn't know actual server load.
2. ecmp-based load balancing
equal cost multi-path routing - allows router to have multiple next-hop routes for same destination.
router configuration:
ip route add 10.0.0.100 \
nexthop via 192.168.1.101 dev eth0 \
nexthop via 192.168.1.102 dev eth0
on each lb server:
# Both LB1 and LB2 have same IP
ip addr add 10.0.0.100/32 dev lo
ip link set dev lo up
how it works? multiple servers configured with same ip. router distributes traffic based on flow (using ips, ports, protocol). makes connections sticky to specific servers.
3. anycast with bgp
how it works? multiple machines advertise the same ip address globally.
key features? routes to geographically nearest instance. leverages internet's shortest path routing. bgp propagates info about which network is reachable via which path.
requirements? bgp authentication (only authorized nodes can advertise ips) and proper prefix configuration.
who uses this? cdns for edge servers, dns providers (google's 8.8.8.8), and any service needing geo-distribution.
final architecture summary
i ain't drawing it again.
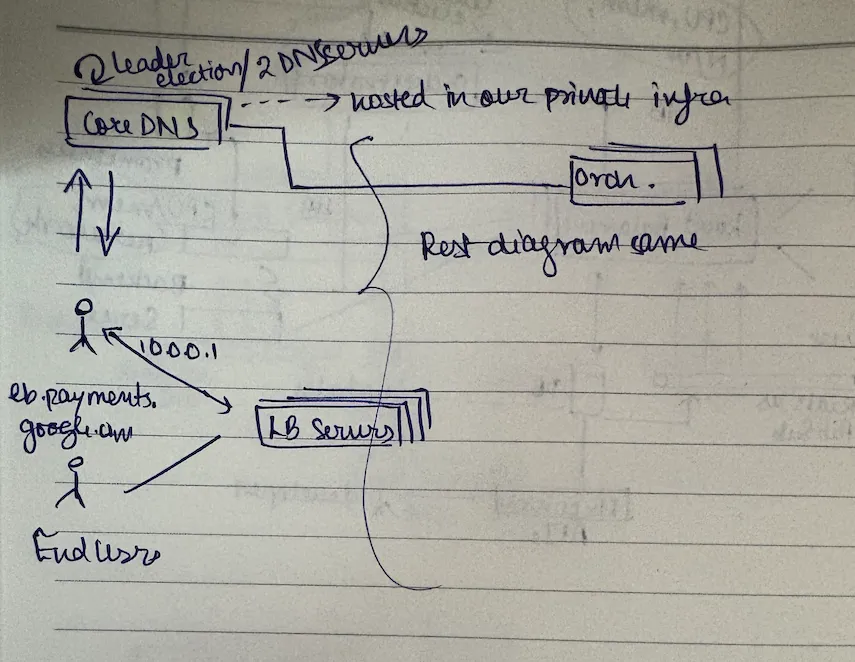
remember: high availability is about having a plan b for your plan b for your plan b. every component should be able to fail without taking down the system. that's the secret sauce.