kv store on relational db: a storage-compute separation story
why another database?
your first question should hit you: "why on earth should we do this?" like dynamodb exists, redis exists, valkey exists, this exists, that exists. why do i have to do this?
but instead of looking at it from a lens of "hey why the world needs it," let's look at it from a mental model perspective. the core essence of this is storage-compute separation. that's our biggest takeaway from this. second takeaway would be elegant queries. so storage and compute separation - this is how you can create a new db every time you want.
consider sparksql - it accepts sql queries but it fetches data from files, apis, databases etc and gives you the result internally. so its not a sql based database but instead we can prolly say it has a sql interface with flexible storage. one more example - dynamodb has a mongodb-like api which is exposed to the user but its built on amazon aurora (a relational db that uses sql). so now you see the compute and storage separation? just tweaking any one of em and you've created a new db.
what we're building
to create a key value (we will call it kv in here for easy reference ) store which speaks in http/rest and stores in mysql. basically we're exposing db as a service with two parts - the computation layer where we expose the http apis to the user, and mysql db as our storage layer. everything will be stored in that mysql. damn this will be exciting and simple to start with.
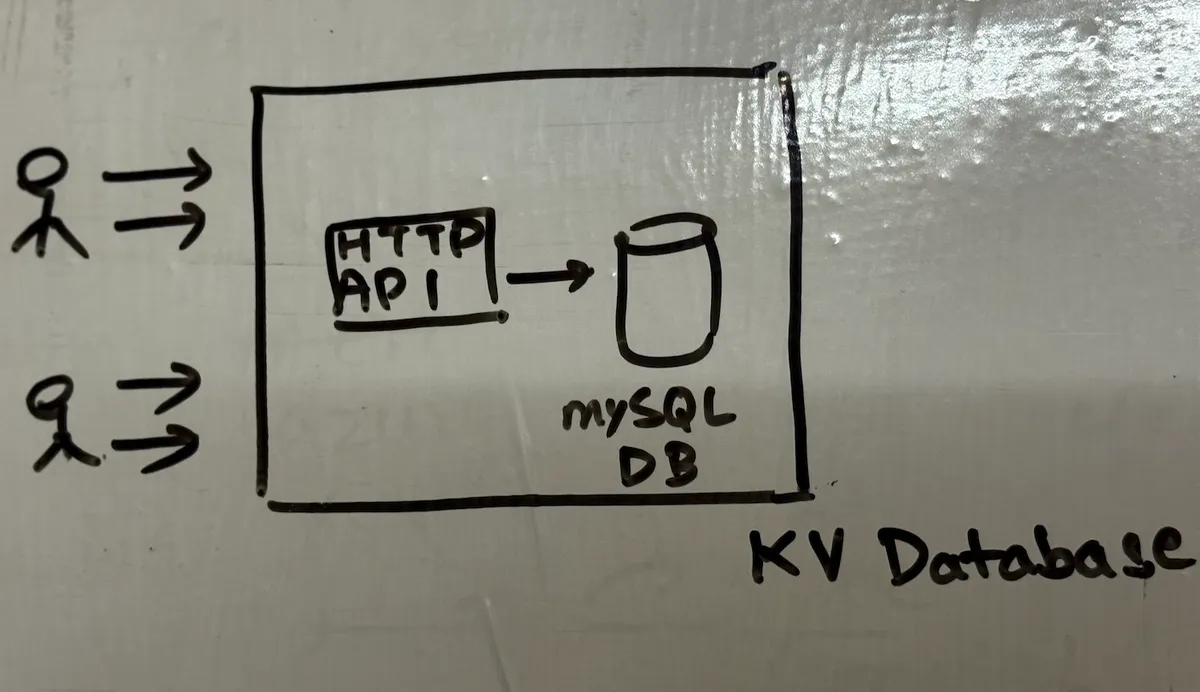
so what are the requirements? we need http based apis - get, post, put, delete. all operations are in sync (to keep stuff simple). some basic schema to start with. and post that we can discuss on scaling, ttl, optimising queries etc.
we keep stuff simple, a simple key value db so we expose 4 rest apis and we want to hold this key value store in the mysql db. here's our schema:
CREATE TABLE store (
key VARCHAR(255) PRIMARY KEY,
value TEXT,
expired_at BIGINT -- absolute timestamp
);
implementing the computation layer
the put operation
aight this is gonna be fun. how will our put operation look like first? put(k1, v1, 300)? - we shouldnt be storing 300sec directly as ttl. since thats wrong (i have seen lots of people doing that mistake). we store absolute time, that is created_at + ttl -> or you can say created_at + 300, so the put query should look like put(k1, v1, now()+300). and mind it we are doing insert command in here.
but can you now think what problem might be in here? well well well its time to triage that.
its simple - if a user logs in for the first time, the insert command works perfectly: INSERT INTO store VALUES ('user_123_session', '{"logged_in": true, "cart": []}', now() + 300);. but if the user refreshes or logs in again with the same session key, we try: INSERT INTO store VALUES ('user_123_session', '{"logged_in": true, "cart": ["item1"]}', now() + 300);. now we get an error since it already exists - the insert command will fail.
so now we know we need to create if the key doesnt exist and update if it already exists. we could wrap this in a transaction to ensure atomicity:
- first
selectto check if it exists - then either
insertorupdate - all wrapped in transaction boundaries
but my friends, we are doing 3 operations internally just to do it. one transaction, one select, one operation of insert or update. lets try to optimise it.
mysql supports upserts which is exactly what we need. we have two options here. option 1 is using REPLACE INTO:
REPLACE INTO store VALUES (k1, v2, now() + 300);
this has reduced our previous query to 1 operation. but the problemmmm - when conflict occurs (that means a key already exists) it internally deletes the row and inserts another row which is slower.
option 2 is using INSERT ON DUPLICATE KEY UPDATE:
INSERT INTO store VALUES (k1, v2, now() + 300)
ON DUPLICATE KEY UPDATE
value = v2,
expired_at = now() + 300;
this is 32x faster (yep i read that on the internet). since instead of delete+insert, it does a proper update when conflict occurs. since in my work i am using prisma currently, theres a simple query by my dear prisma orm which is prisma.<table_name>.upsert.
the get operation
lets try to get the users who havent been expired. for that the query would look like:
SELECT * FROM store
WHERE key = k1 AND expired_at > NOW();
dead simple. we check the key and make sure its not expired. nothing fancy here.
the delete operation
again we have 2 options - hard delete or soft delete. i have already written about why soft delete is ideal (Link). in soft delete you just update a column to indicate it has been soft deleted and later on using batch delete you clear the data. here is the example:
UPDATE store SET expired_at = -1
WHERE key = k1 AND expired_at > NOW();
so why expired_at = -1? this will help us later determine and provide stats to user about which key has been expired naturally vs deleted by the user. you might ask, tautik - where can i find this in practice? umm lots of cases:
- when a user session has been timed out
- application tries to delete a cache entry that already expired
- cleanup processing that we run on already-cleaned data
its micro optimisation because it only helps in edge cases, but when you have millions of operations, these edge cases add up.
batch deletes and optimisation
so how should we ideally batch delete? well make sure to always use ORDER BY key, not ORDER BY expired_at. since when we are deleting the row it would require minimal rebalancing because the keys that are getting deleted are from a closed set of ranges. thus multiple keys on the same page might be deleted with this iteration:
DELETE FROM store
WHERE expired_at < NOW()
ORDER BY key
LIMIT 1000;
now what further optimisation can we do? think about it. if we have 1mil rows, and we apply above query - we need to look for each row which satisfies this condition. since it will do a full table scan without the indexes. after that it will get those rows, sort it, and delete the first 1k rows from above query.
what happens with an index on expired_at? first create the index: CREATE INDEX idx_expired_at ON store(expired_at);. now whenever we run the delete query, our db will do lookup on index to quickly find the rows where expired_at < now(), and only reads 50k expired rows (not all 1 mil, and yep assuming 50k rows are expired, all are assumptions). and then we delete the first 1k rows. dead simple. i will write more about indexes later on lol. its so fun. everything is fun. aight back to the topic.
ps: if you dont know, we have reduced the time complexity from o(n) to o(log n + k) after doing quick index lookup + reading only matching rows. so what we can learn - you can always create indexes on columns you use in where clauses, especially for cleanup operations that run frequently.
scaling this thing
yeppie, this is the fun part. so one way i can think of doing this is by just scaling the kv computation layer (for our easy use, lets call it kv api server). but again wrong - what if we are unnecessarily scaling stuff but our db is not able to handle that load? thats why we always do bottom up.
lets start bottom up by trying to scale our storage layer. so what if we have 90:10 read requests? we simply add READ REPLICAS to handle those reads and lets add database proxy in between as well to route the requests from computation layer to storage layer.
but then here comes the problem - if we have read replicas, we know we are signing up for staleness. but then how will we ensure that every client around the world receives accurate data? like which client should we route to the replicas, which client to master? i know right this computation internally can become such an overhead ahh. so lets do this like how dynamodb and other services do. the right solution is: let the user decide!
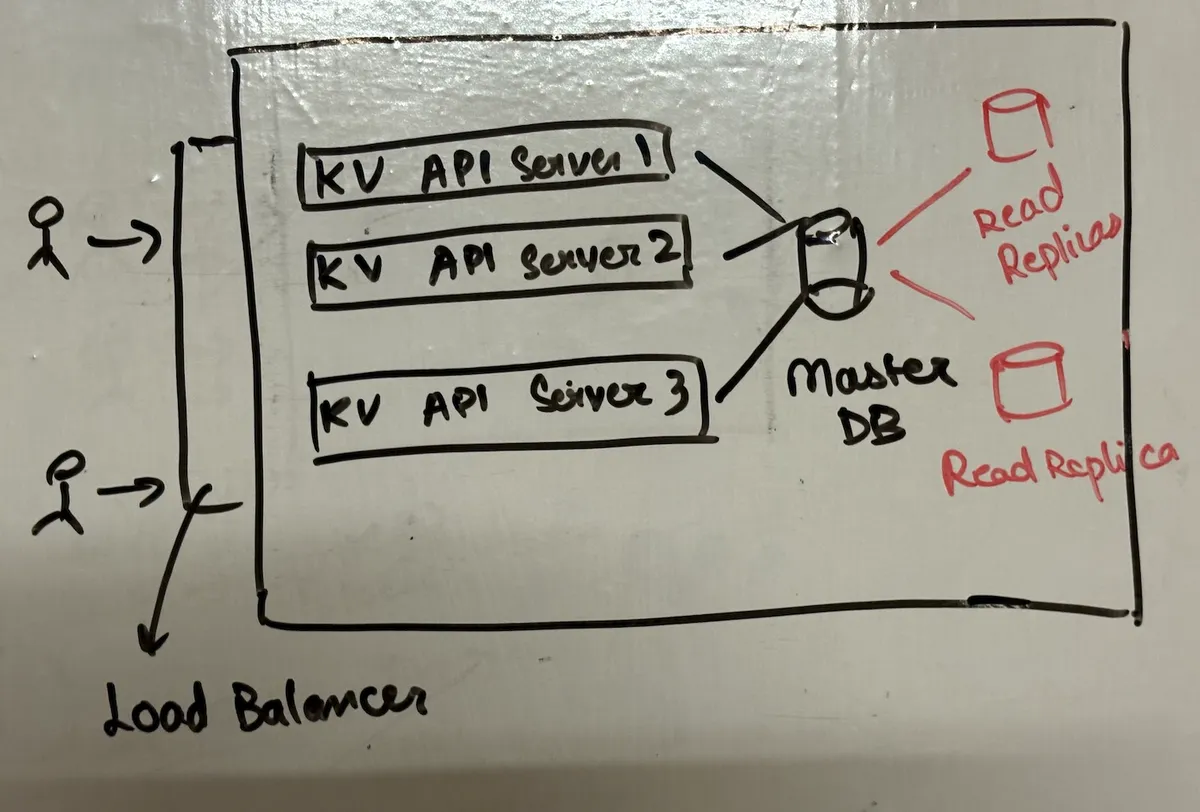
GET /key?consistent=true → goes to master
GET /key → goes to replica (default)
i know this is funny, but why complicate stuff. see the philosophy is: "you are paid to solve a problem and not necessarily write code to solve it". i should prolly tweet about this. so yep dont over optimize stuff.
handling write scaling
so now that we are done with scaling and handling reads, lets think about writes. for writes we know the request goes to the master. but when the master cant handle the write load, we basically shard the database.
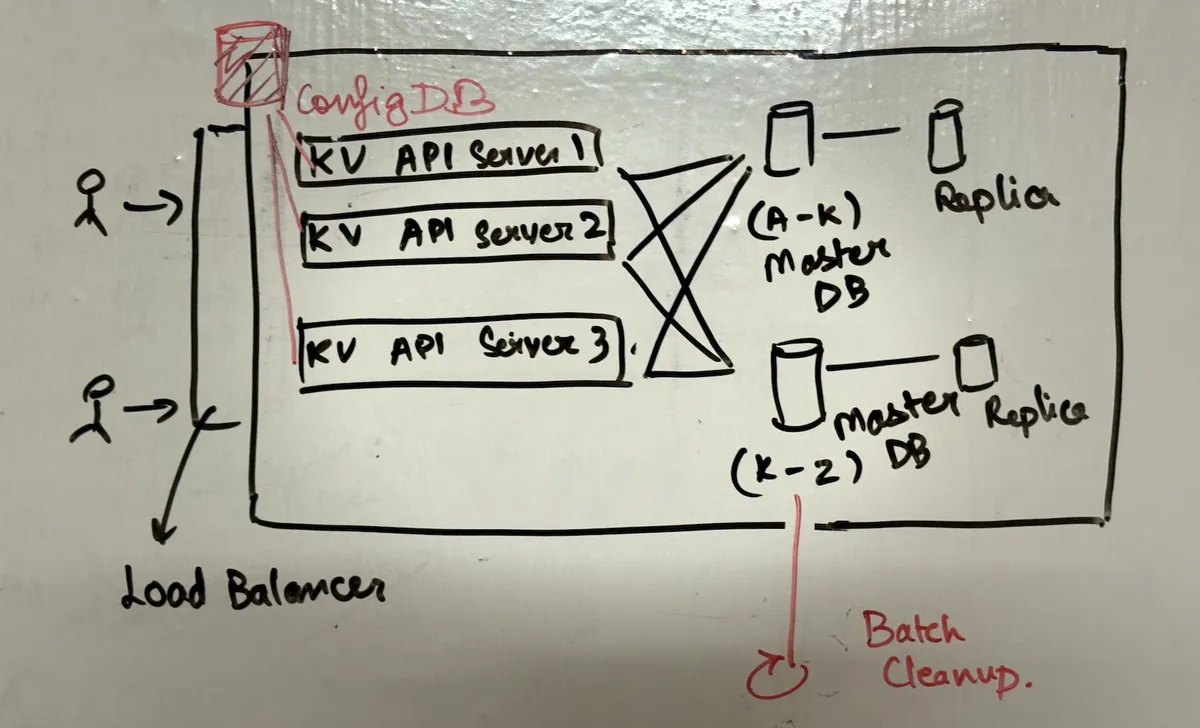
for this we have partition strategies. there are 3 basically - hashing, static, and range based. so lets have a config db at the start - our computation-layer (or the proxy layer if you have) now refers to the config db which contains the rules for where to route the user.
static mapping: one metadata entry for each key in config db. but imagine if this is key value - we will be storing for each of the entry in the db. if you have million keys, will we store million entries in our config db? hell naw, its too much metadata explosion
hash based partitioning: another end of the extreme, zero metadata. but the problem is if hash function changes, we need to re-partition everything - huge data movement:
shard = hash(key) % number_of_shardsrange based partitioning: lies in between of static and hash based. now we have minimal metadata, and its just simple:
A-K → Shard 1 L-P → Shard 2 Q-Z → Shard 3
so depending upon metadata size, key control and flexibility we choose one. nothing is best. everything depends upon our usecase.