03 MAY 2026 · 18 MIN READ
id generators - from `Date.now()` to snowflake
aight so today we're talking about id generators. seems boring on paper, but stay with me — this is one of those topics where every line of complexity comes from a real production problem someone hit at scale. and the cool part is the entire problem statement collapses to: write a function that spits out something unique every time it is invoked. that's it. no service, no microservice, no fancy box.
actually that's the first thing you should internalize. you don't need a microservice for this. everyone wants to draw a box and call it id-svc but please don't do that until something forces you to. think of yourself as the only engineer who's gonna build, deploy, and on-call this thing. suddenly your appetite for new boxes drops to zero. good.
what you'll take away
quick pointers so you know what to look for as you read:
- function first, service later. don't reach for a microservice until something forces you to.
- whatever causes a collision becomes a differentiator. two machines collide → machine id. two threads collide → counter. mechanical pattern.
- timestamp on the left = rough sortability for free. snowflake, mongo objectid, instagram — all do this.
- distribution + strict monotonicity + high throughput → pick two. spanner buys all three, but only with atomic-clock hardware.
- uuids are an index-bloat tax — except when they aren't. bad for mysql reads, perfect for cockroach writes. depends on the db.
- logical shards on physical hosts = cheap hot-shard rebalancing. instagram's trick. same idea elasticsearch uses.
- relax the right constraint for your usecase. twitter dropped strict monotonicity, cockroach dropped sortability, flickr dropped "no central service". each got something back.
but why do we even need our own ids?
your first question should hit you - if databases give us auto-increment ids, why are we even having this conversation?
so imagine a sharded database. you've got 4 mysql shards each holding a slice of your posts table. if every shard runs its own auto-increment, you're gonna get id 1, 2, 3 in shard A and id 1, 2, 3 in shard B. when you read a post by id 2, which one do you mean? lol. collision.
so the moment you shard, you cannot rely on the database to give you unique ids. you have to provide the id yourself at insert time. that's the whole motivation. there are other places too (event sourcing, distributed logs, whatever) but sharded dbs is the canonical one.
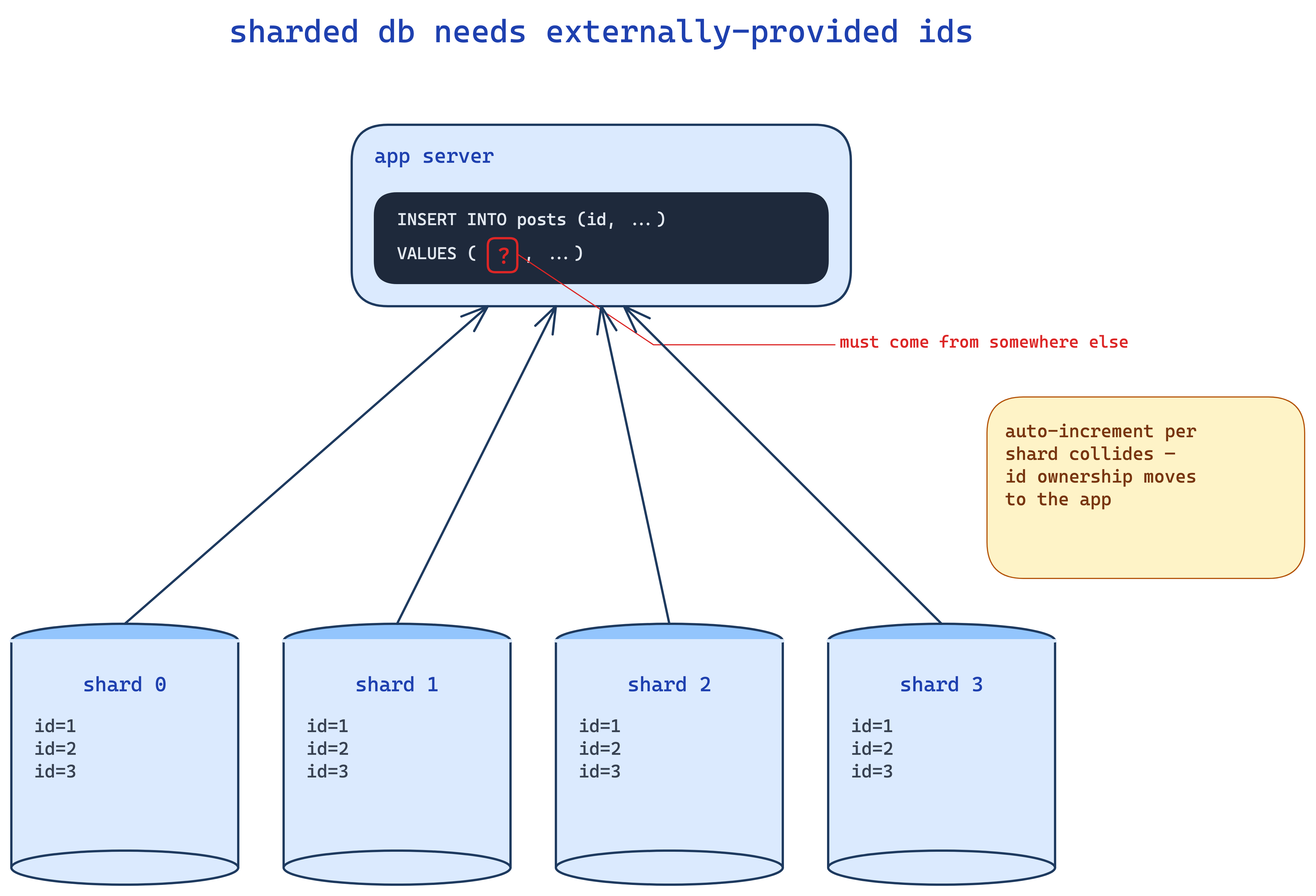
ok so what do we want? a function get_id() that returns something unique every single time. let's build it.
time as id - dead simple
what's unique through time? well, time itself. it always moves forward. so the world's simplest id generator:
func get_id() {
return get_epoch_ms()
}return current epoch milliseconds. done. ship it.
this works for so many use cases that it's actually criminal how often people skip past it.
your solution should be functional with respect to your constraints. nobody gets to call your design stupid because they don't know your constraints.
aight back to get_epoch_ms(). what's the catch?
multi-machine collision
what if two machines invoke this function in the same millisecond? same id. collision. damn.
fix: prepend the machine id.
func get_id() {
return concat(machine_id, get_epoch_ms())
}so machine m1 at time 1729 returns m1-1729. machine m2 at the same instant returns m2-1729. no collision. each machine knows its own id at boot.
threads happen
ok now what if my program has threads, and two threads on the same machine invoke get_id() in the same millisecond? collision again. you've got two ways out:
- add
thread_idas another differentiator - add a static counter that gets atomically incremented every call
the counter approach is cleaner imo. you've got one int, every call does an atomic counter++, and you append it to the id:
int counter = 0
func get_id() {
return concat(machine_id, get_epoch_ms(), counter++)
}now even within the same ms on the same machine, two calls get different ids because the counter moved.
but wait. think tautik think. if i already have a counter that always moves forward, what is the timestamp even doing here?
nothing. it's redundant. so just rip it out:
int counter = 0
func get_id() {
return concat(machine_id, counter++)
}this generates m1-0, m1-1, m1-2, ... each id is leaner (no timestamp bytes), still unique, still atomically safe. and on a 64-bit counter you'd have to invoke this at insane rates to ever wrap around.
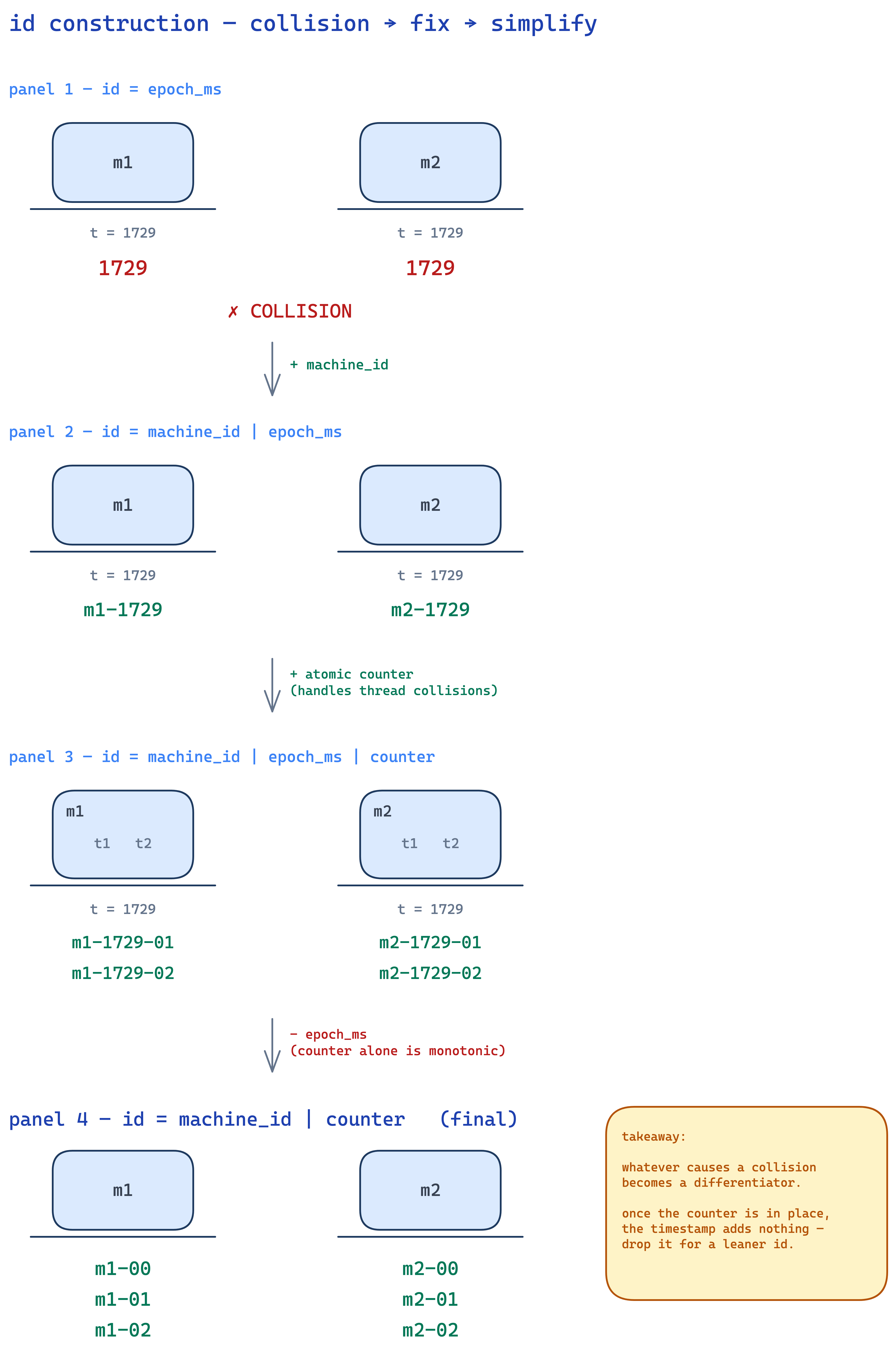
✽ RECALL two machines collide in the same millisecond, then two threads on the same machine collide. what's the fix in each case, and why does the timestamp become dead weight once you add a counter?
whatever causes the collision becomes a differentiator — machines collide → prepend machine id, threads collide → append an atomically-incremented counter. and once you have a counter that only ever moves forward, the timestamp contributes nothing to uniqueness anymore, so concat(machine_id, counter) is leaner and just as safe. a 64-bit counter won't wrap at any sane rate.
but counters are volatile
so the problemmmm. the counter is in memory. if the process crashes or restarts, it goes back to 0. and now you start regenerating ids you've already issued. catastrophic.
fix: persist it. easy.
now most people's brain immediately goes "let me put it in a database." why?? bro you just need durability. that's the whole property you need. a local file gives you durability. why are you inducing a network call, a sql parser, a query planner, an execution plan, a commit protocol... just fwrite() to a file. open file, write counter, flush, close. or keep it open and keep flushing. that's all you need.
int counter = load_from_disk()
func get_id() {
counter++
save_to_disk(counter) // disk i/o on every call
return concat(machine_id, counter)
}this is the biggest disease in tech tbh. people see "durability" and reach for postgres. you are paid to solve a problem and not necessarily write code to solve it. if a 4-byte file does the job, write a 4-byte file.
but disk i/o on every call?
yeah that's slow. millions of get_id() calls = millions of fsyncs. not gonna fly at any reasonable throughput. so we batch.
instead of flushing every increment, flush every 1000. and here's where it gets a little subtle:
int counter = load_from_disk() + 1000 // flush_frequency
func get_id() {
counter++
if (counter % 1000 == 0) {
save_to_disk(counter)
}
return concat(machine_id, counter)
}look at line 1. on startup, you don't load and start from whatever_was_on_disk. you load and add flush_frequency. why?
because between the last successful flush and the crash, the counter moved forward by some amount you don't know. could be 1, could be 999. so to be safe you assume it moved by the full flush_frequency. add that, and your starting value is guaranteed to be a value never issued before.
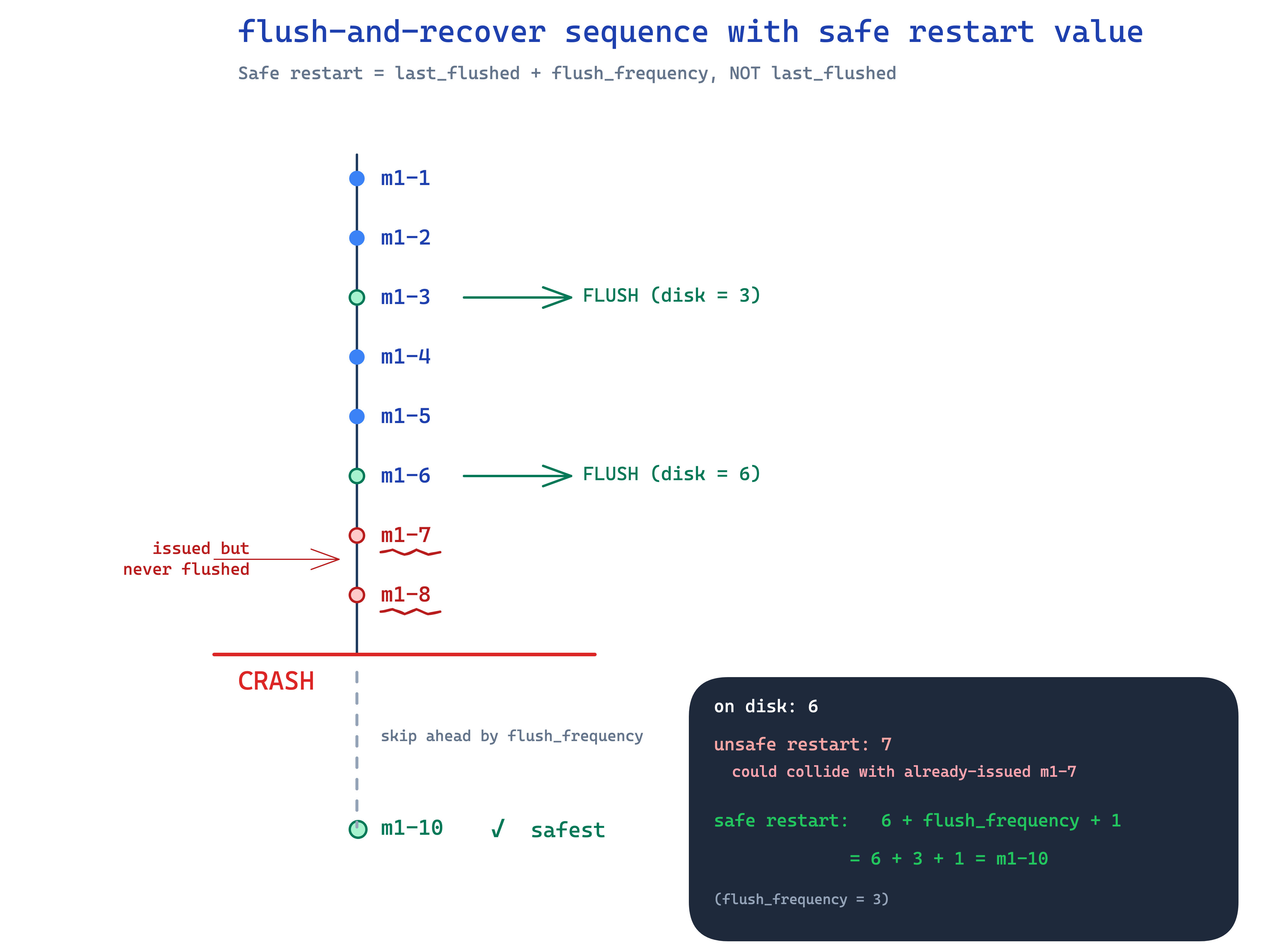
people sometimes try to do this time-based ("flush every 5 seconds") and then on recovery do "historical analysis" of how many ids were typically generated in 5 seconds. don't. that estimate will be wrong eventually and you'll regenerate an id. go frequency-based. opposite of time-based. with frequency, the math is exact.
so now we've got: lean ids, durable counter, batched i/o, no service. for a single machine this is genuinely solid. but the moment we want monotonically increasing ids, the rules of the game change.
✽ RECALL your counter flushes to disk every 1000 increments and the process crashes between flushes. why do you restart at last_flushed + flush_frequency instead of last_flushed, and why is time-based flushing a trap?
between the last flush and the crash the counter moved forward by some unknown amount up to 999, so you assume the worst — add the full flush frequency and your restart value is guaranteed never issued before. time-based flushing ("every 5 seconds") forces you to estimate how many ids fit in the window on recovery, and that estimate will eventually be wrong and you'll reissue an id. frequency-based math is exact. and note: a local file gave you all of this — durability never required a database.
monotonic ids - why bother?
monotonically increasing means id_{i+1} > id_i for every i. always. no dips. no out-of-order.
why do we want this? conflict resolution. who came first.
imagine elasticsearch with multi-version document updates. transaction T1 sets a=20, transaction T2 sets a=30. they arrive at your search index out of order because you're consuming in parallel. how do you know T1 came before T2? well... if their ids are monotonically increasing, you just compare. id_T1 < id_T2, so T1 was earlier, and when applying out-of-order updates you keep the latest version and discard the older one. last-write-wins.
without monotonicity? you have no way to order them. chicken and egg.
strict vs rough monotonicity
strict monotonicity in a distributed system is brutally hard (we'll see why in a sec). but rough monotonicity is easy. just put the timestamp on the left-hand side of your id.
id = concat(get_epoch_ms(), machine_id, counter)LHS = most significant bits. since the timestamp moves forward every millisecond, the most significant bits dominate the ordering. ids generated later are almost always numerically larger than ids generated earlier. within a single ms there might be reshuffling between machines (machine_id breaks ties on the right) but at the macro level, monotonic.
this is the pattern. once you internalize it, you'll see it everywhere. snowflake? timestamp on LHS. mongodb objectid? timestamp on LHS. instagram? timestamp on LHS. universal.
✽ RECALL why does putting the timestamp in the most significant bits of an id buy you rough — but only rough — monotonicity, and what does that sortability unlock?
the high bits dominate numeric ordering and the timestamp only moves forward, so ids generated later are almost always numerically larger — snowflake, mongo objectid, and instagram all lean on exactly this. it's only rough because within a single ms the machine-id bits reshuffle the tail, and clock skew across machines causes dips. the payoff is cursor pagination: WHERE id > :last_seen LIMIT n costs the same on page 2 and page 200,000, while OFFSET walks and discards every skipped row.
the clock skew bossfight
so why doesn't rough monotonicity become strict at scale? clock skew.
picture 4 machines. machine ids 2, 4, 7, 9. they're all running NTP but their clocks have drifted slightly:
- m2 thinks it's
time=23 - m4 thinks it's
time=24(running fast) - m7 thinks it's
time=23 - m9 thinks it's
time=23
at "the same instant" we invoke get_id() on all four. results:
m2 → 232
m4 → 244
m7 → 237
m9 → 239not monotonically increasing! 244 came out before 237 in wall-clock order. dip.
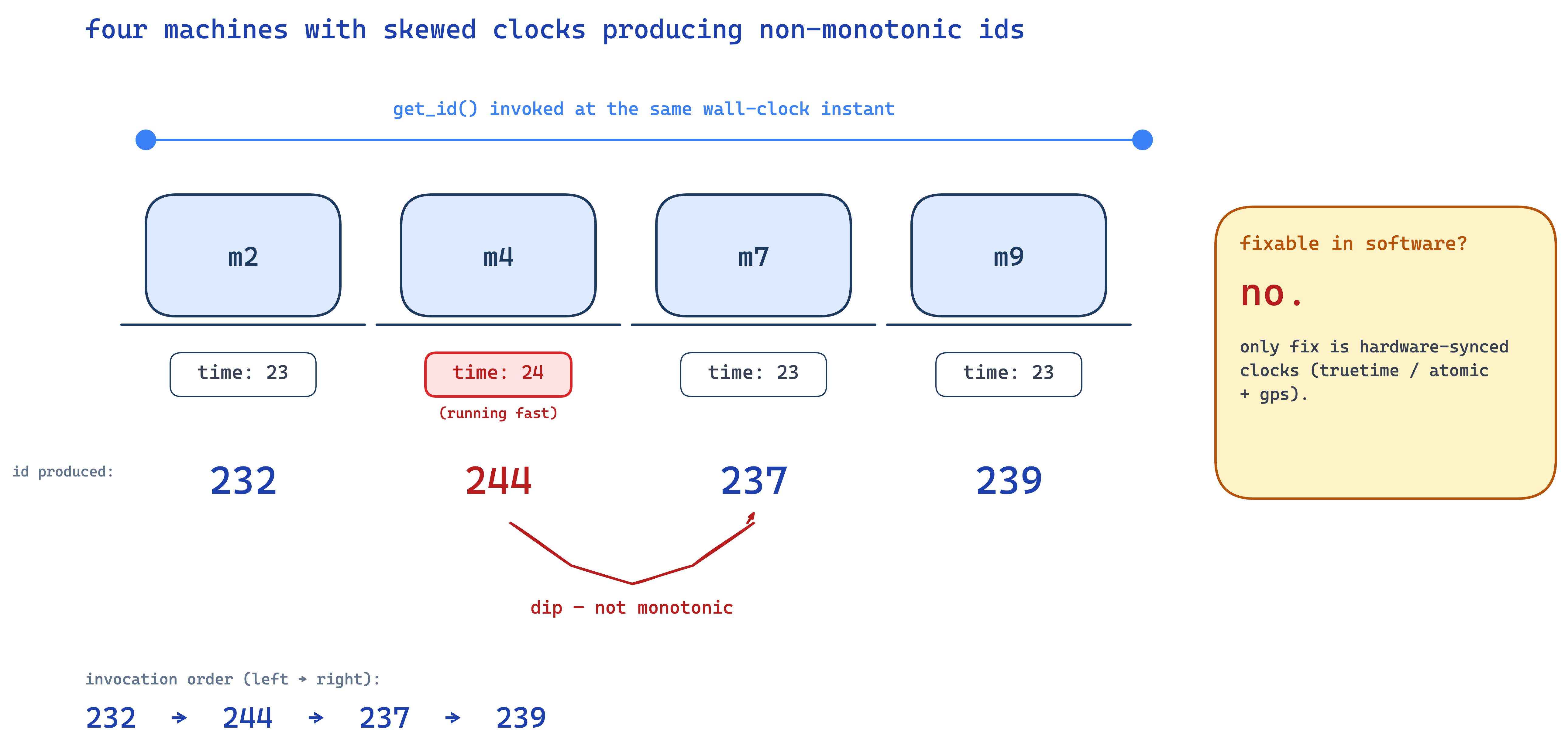
and there's nothing you can really do about clock skew with software alone. NTP doesn't make clocks identical, just close-ish. the only company i know of that genuinely fixed this is google with truetime in spanner — and they did it by literally putting atomic clocks and gps receivers in their datacenters. specialized hardware. who has that luxury? nobody else really.
the central service trap
so you go: "ok let me have ONE machine generate ids. no clock skew, no problem."
cool. now you have a single point of failure. machine dies → no ids → entire service down. so you add a second id server behind a load balancer for redundancy.
now your two id servers need to gossip to agree on ranges. server A picks 102, gotta tell server B "don't pick 102". server B picks 105, gotta tell A. on every single id. and reservations have to be consistent. this is essentially a distributed consensus problem and your throughput just collapsed.
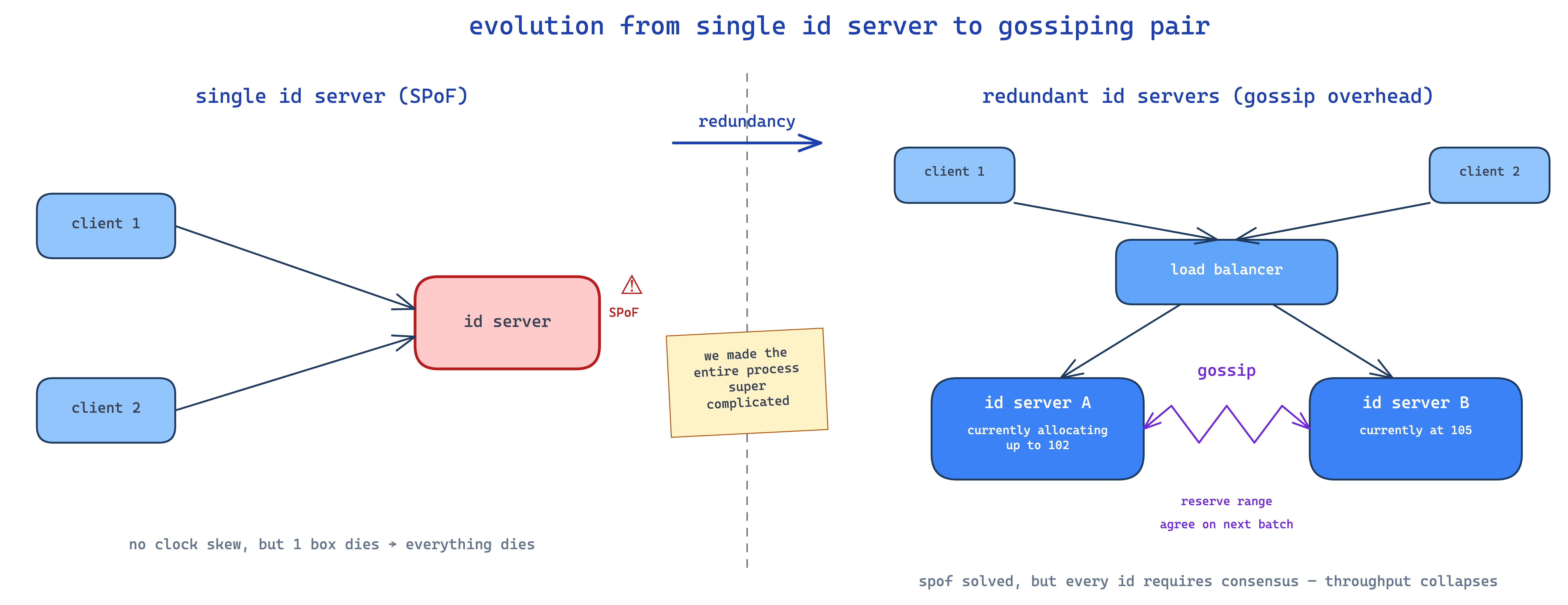
so we end up with this fundamental result, which is honestly kinda beautiful in how clean it is:
there is no way to distribute id generation, guarantee strict monotonicity, AND have high throughput — without specialized hardware.
pick any two. you cannot have all three. real-world systems almost universally drop monotonicity (settle for rough/sortable) so they can keep distribution and throughput. that's what twitter, instagram, discord, sony etc all do.
✽ RECALL you want distributed generation, strict monotonicity, and high throughput all at once. why can't software alone get you all three, and which one do real systems drop?
clock skew kills distributed strict ordering — NTP keeps clocks close-ish, never identical, so a machine running fast stamps "later" ids that come out earlier in wall-clock order. centralizing on one machine fixes skew but creates a SPOF, and adding a second id server means gossiping a consistent reservation for every single id — a consensus round that collapses throughput. only specialized hardware escapes the triangle (spanner's truetime, with atomic clocks and gps in the datacenter). everyone else — twitter, instagram, discord — drops strict monotonicity and settles for rough.
case study 1: amazon's batched ticket service
amazon does the central-service thing but they make it cheap. one mysql table:
service counter
------- -------
orders 500
payments 0when an order-service pod boots up, it calls get_id_batch(500). the id service does an atomic update on the row, bumps counter from 500 to 1000, and returns the range [501, 1000] to the caller.
now that pod owns 500 ids locally. it doesn't talk to the id service again until it's used 80% of them. then it asks for the next batch.
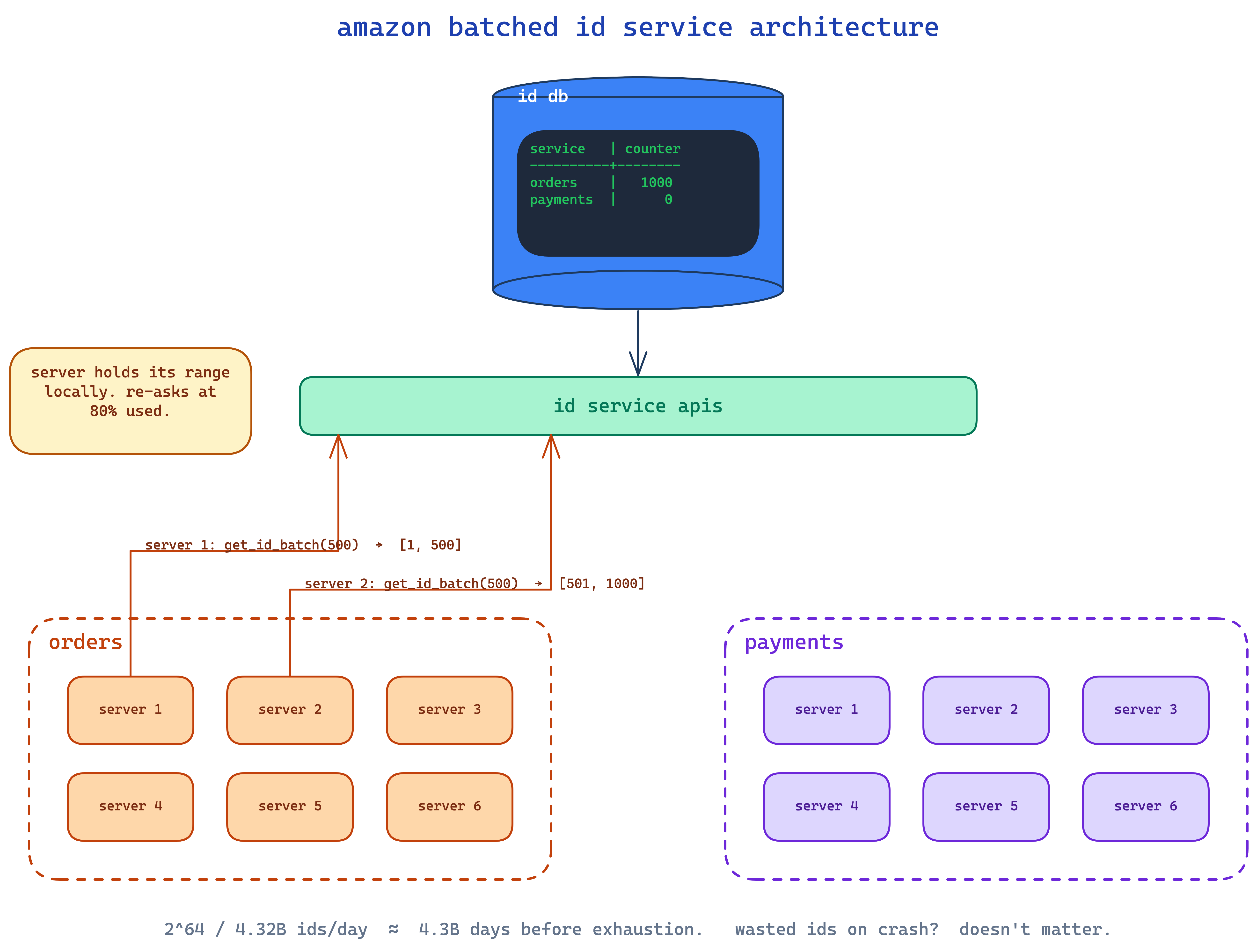
what if the pod crashes after using 10 of its 500 ids? you lose the remaining 490. who cares. counter is a 64-bit unsigned int. let's do napkin math: 100 servers each burning 500 ids/sec = 50,000 ids/sec ≈ 4.32 billion ids/day. 2^64 / 4.32 billion = ~4.3 billion days. and even if 50% of every batch is wasted from restarts, you've still got billions of days. the calculator overflows before your id space does.
don't be miserly about wasting ids. trying to deterministically reuse "leaked" ranges adds enormous complexity for zero practical benefit. let them die. ship faster.
✽ RECALL in amazon's batched ticket scheme, a pod grabs a batch of ids and crashes after using a handful. why is "let them die" the right call instead of reclaiming the leaked range?
the counter is a 64-bit int — even with half of every batch wasted to restarts, napkin math says the id space outlives you by billions of days. batching already bought the real win: a pod touches the central service once per batch instead of once per id, so generation stays local and fast. deterministic reuse of leaked ranges adds genuine complexity for zero practical benefit.
case study 2: why not just UUIDs?
uuids are 128-bit integers. they're random. they're easy. why aren't we using them?
index bloat.
think about how an index is stored in mysql. for an index on column name, the index leaf is essentially (name, primary_key) → row. so if your primary key is a 4-byte int, an index entry is 4 + 4 = 8 bytes. if your primary key is a 16-byte uuid, an index entry is 4 + 16 = 20 bytes. 2.5x larger.
multiply that across every index on every table. now your indexes are 2.5x bigger. and here's the killer: a database is fast only when its indexes fit in RAM. if your indexes spill to disk, every lookup becomes a disk seek before you even get to fetching the row. you've turned a memory operation into a disk operation. your query latency just exploded.
so at scale, uuids are a tax you pay on every read. not worth it. (also they're not sortable, which kills cursor-based pagination — more on that in a sec.)
the cockroachdb counter-example
hold on though — cockroachdb's docs literally recommend using uuids as primary keys. why?
because cockroachdb is range-partitioned. data is sorted by primary key and split into ranges across nodes. if your pk is monotonically increasing, every insert hits the node that owns the latest range. that one node becomes a hotshard, the other N-1 nodes do nothing. you've defeated the entire point of a distributed database.
with random uuids, inserts are spread evenly across all nodes. throughput scales horizontally.
so the same property (randomness) that made uuids bad for sharded mysql makes them good for cockroachdb. nothing is best. everything depends on your usecase.
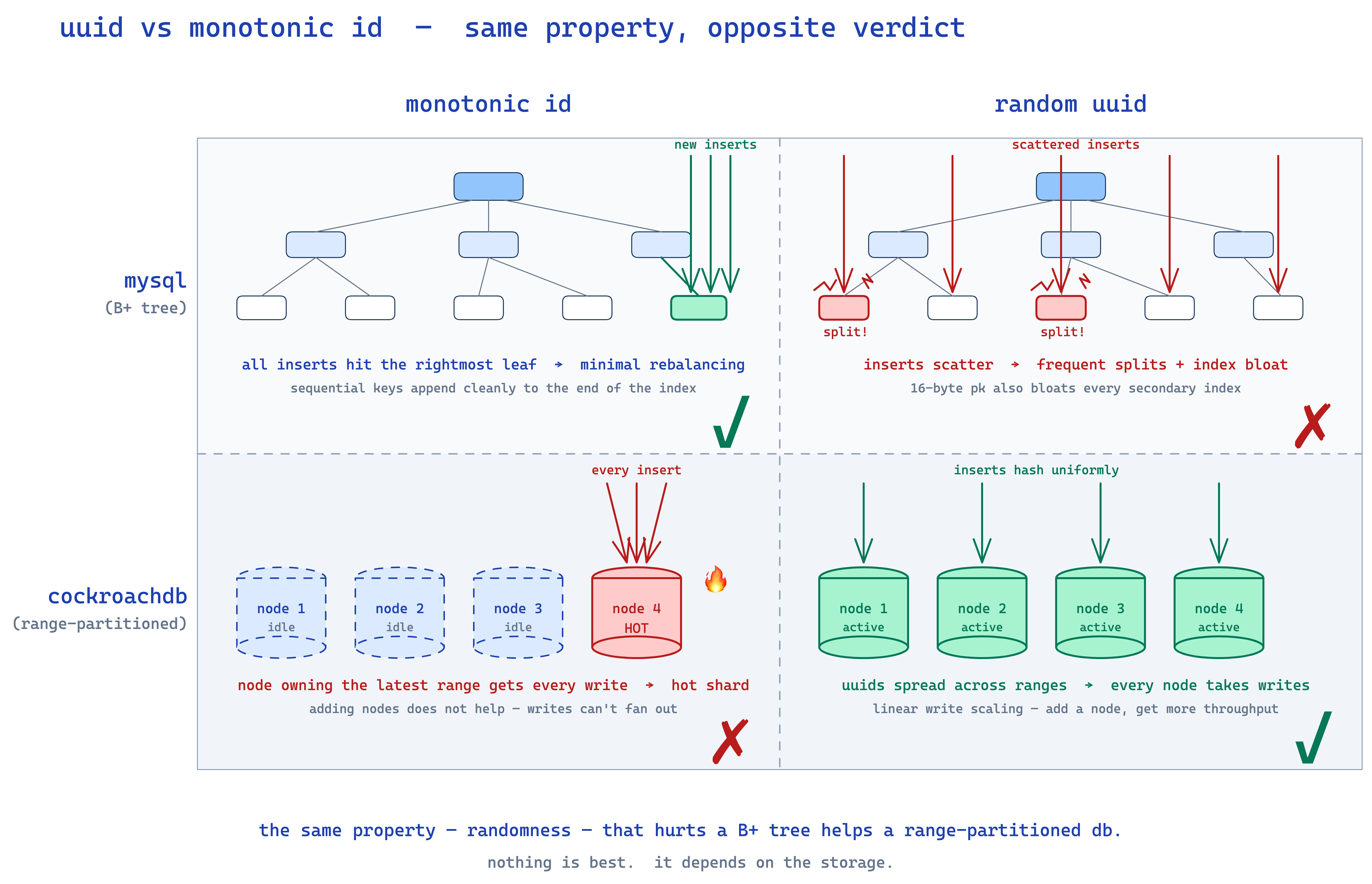
✽ RECALL why are random uuids a tax on every read in sharded mysql, yet the recommended primary key in cockroachdb?
in mysql every secondary index entry carries the primary key, so a fat uuid pk bloats every index on every table — and the moment indexes spill out of RAM, each lookup eats a disk seek before you even fetch the row. cockroach is range-partitioned by pk: a monotonically increasing key funnels every insert to the node owning the latest range — one hotshard, N-1 idle nodes — while random uuids spread writes across the cluster. same property, randomness, opposite verdict. nothing is best; everything depends on the usecase.
case study 3: flickr's database ticket server
flickr did something a lot of people roll their eyes at, but it's actually elegant. they spun up a dedicated mysql server whose only job was to run auto-increment.
CREATE TABLE tickets (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT
)every time someone wants an id, they go to that mysql, do an insert, get back the auto-incremented id, and use it as the pk for their actual sharded data store. it's effectively the central-id-service we discussed, just implemented with mysql's existing primitives instead of writing one from scratch.
was this the most elegant thing ever? no. did it work for flickr at their scale? yes. that's the bar.
case study 4: twitter snowflake
ok now my favorite. twitter went the other direction — no service at all.
snowflake is a 64-bit integer split into 3 chunks:
- 41 bits: epoch milliseconds (since some custom epoch like 2010)
- 10 bits: machine id (so up to 1024 machines)
- 12 bits: per-machine counter
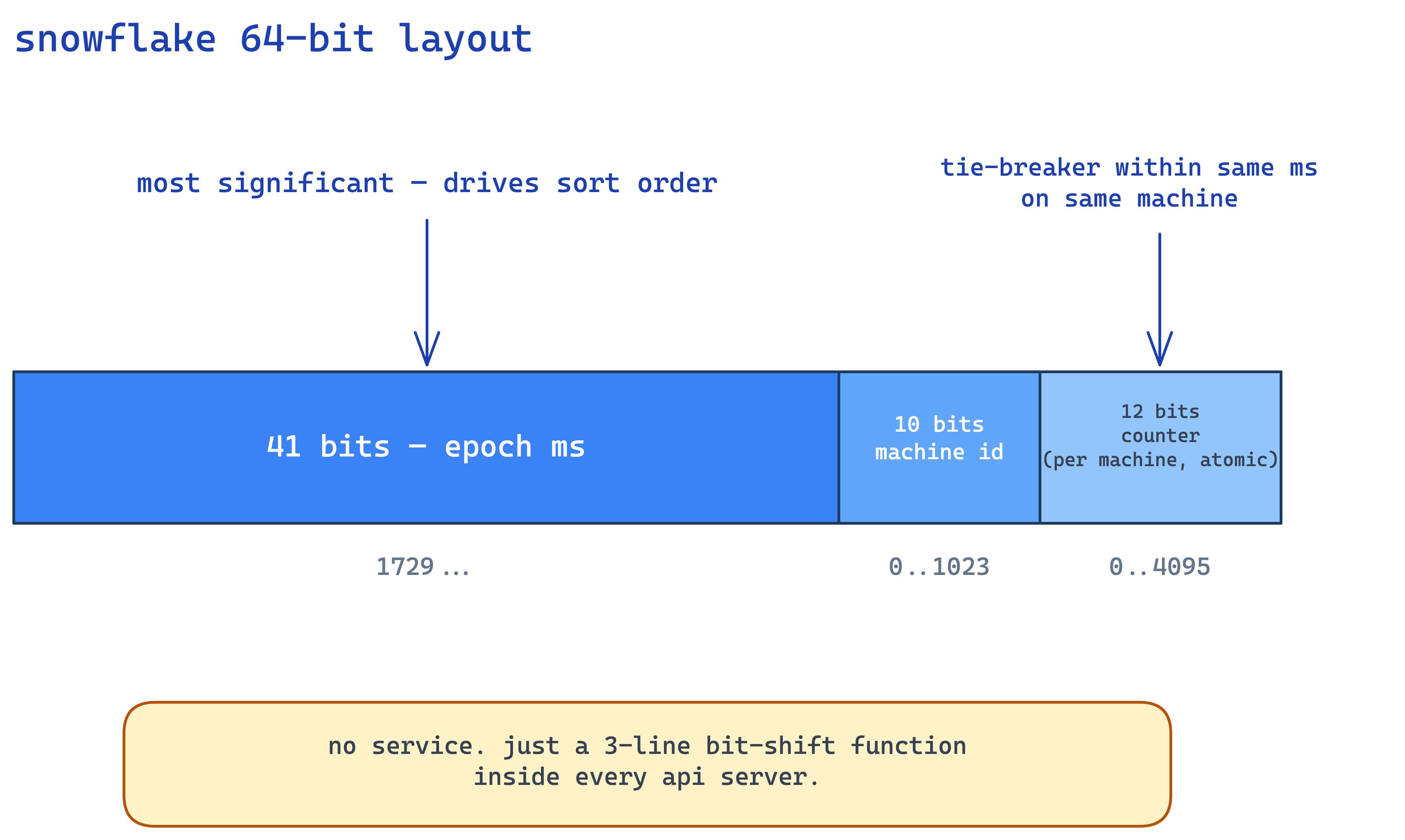
generation is literally 3 lines of bit manipulation. there is no service. every api server that wants to write a tweet just runs get_id() locally as a function call. machine_id is assigned at boot via a tiny coordination service (think: a table with 1024 rows, claim one, release on shutdown). that's the only network hop, and it happens once per pod lifetime.
and because the timestamp is on the LHS, snowflake ids are roughly sortable. which gives you something kinda magical for pagination.
the pagination payoff
most apps paginate with LIMIT n OFFSET k. OFFSET k is brutal — the database walks the first k rows just to skip them. as you go deeper into the result set, the query gets linearly slower. classic graph: deeper → slower.
but if your ids are roughly sortable, you can paginate by id instead:
SELECT * FROM tweets WHERE id > :last_seen_id LIMIT 5every page is O(log n + k). constant with depth. doesn't matter if you're on page 2 or page 200,000, the query takes the same time.
this is why twitter's api uses since_id instead of offset. it's why dynamo uses LastEvaluatedKey. it's why mongodb pagination patterns push you toward _id > :cursor. cursor-based pagination is the natural friend of sortable ids and they unlock each other.
case study 5: instagram's snowflake variant
instagram took twitter's idea and made one really clever change. their layout:
- 41 bits: epoch milliseconds (since jan 1 2011)
- 13 bits: db shard id
- 10 bits: per-shard sequence number
notice — they replaced "machine id" with "db shard id". the id encodes where the row lives.
and the genius is what they do with logical shards on physical servers. instagram has thousands of logical shards (basically CREATE DATABASE insta_0, CREATE DATABASE insta_1, ... in postgres) but only ~10-15 physical postgres servers. each physical server holds many logical shards.
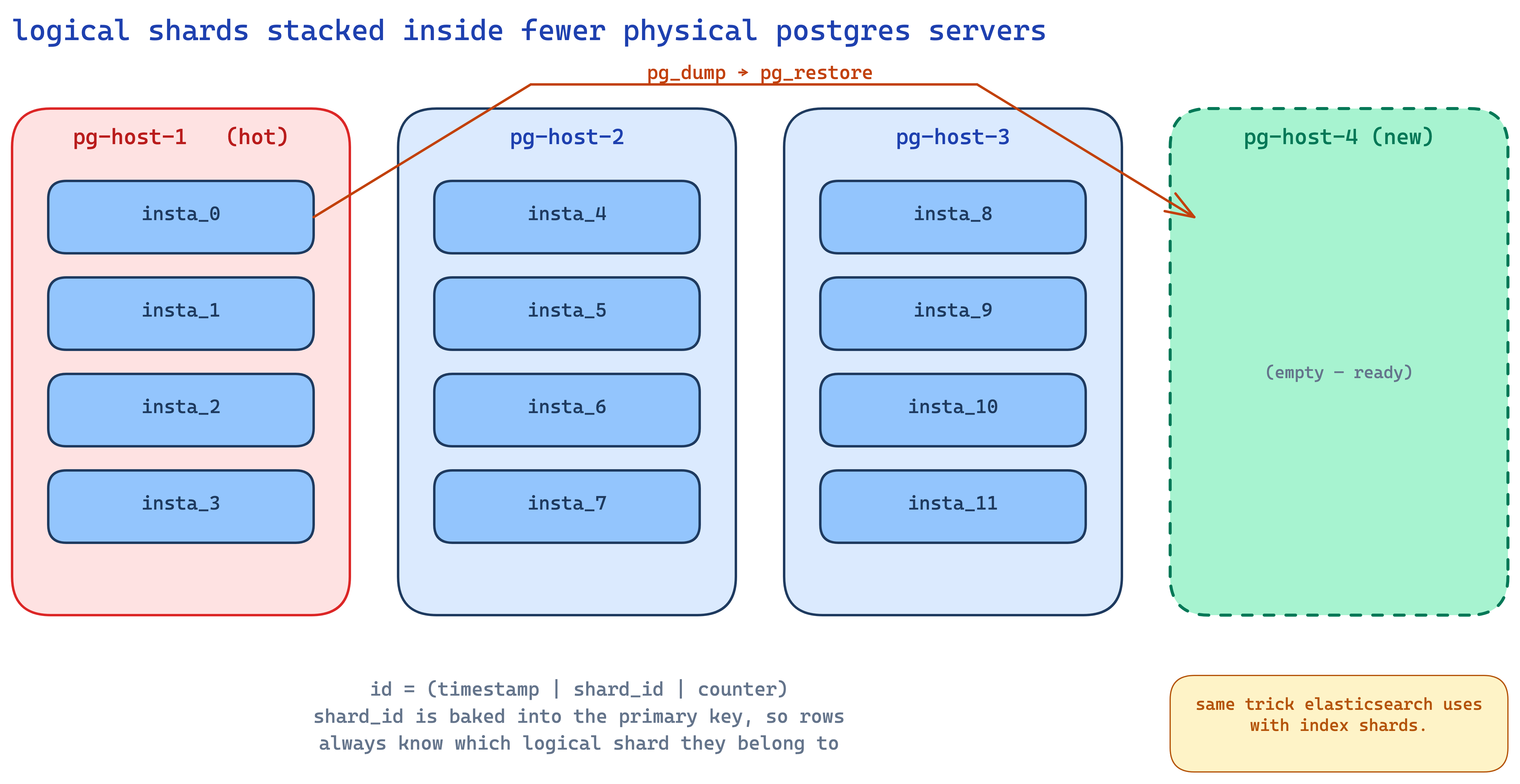
why? because handling a hot shard becomes trivial. when one physical server starts getting hot, you spin up a new physical box and just pg_dump one of the logical shards from the hot box and pg_restore it on the new box. dump-and-load operates on a whole directory at the file level — way faster than iterating row-by-row to figure out who-goes-where like you'd have to do if your physical and logical shards were 1:1.
this is the same trick elasticsearch uses with shards. the underlying pattern: have many small logical units inside fewer large physical containers, so you can move logical units around when load shifts. extremely clean.
and the id generation lives inside the database — it's a stored function set as the DEFAULT for the id column. when you insert a post and don't specify an id, postgres calls the function, which packs (timestamp | shard_id | counter) and that becomes the row's pk. zero service, zero network calls, all happening inside the insert transaction.
✽ RECALL instagram runs thousands of logical postgres shards on only ~10-15 physical servers. what does that indirection buy them when one box runs hot?
rebalancing becomes trivial — pg_dump one logical shard off the hot box and pg_restore it on a fresh one. dump-and-load moves a whole directory at the file level, no row-by-row resharding to figure out who-goes-where. if logical and physical shards were 1:1 you'd have none of that freedom. it's the same trick elasticsearch uses: many small logical units inside fewer large physical containers, so you can move the units around when load shifts.
closing thoughts
the thing i keep coming back to is — id generation seems trivial until you actually try to ship it at scale. then every constraint you add (durability, monotonicity, distribution, throughput) tightens the screws and forces tradeoffs. the entire history of this space is people relaxing the right constraint for their specific use case:
- twitter relaxed strict monotonicity → got rough sortability + zero-service generation
- instagram relaxed strict monotonicity AND embedded shard info → got hot-shard rebalancing for free
- cockroachdb relaxed sortability entirely (uuids) → got distributed write throughput
- flickr relaxed "no central service" → got auto-increment for free without writing code
- amazon relaxed "no wasted ids" → got cheap, simple, robust batching
the courses portal i mentioned earlier? we relaxed everything except uniqueness. 6 random characters. ships every release. nobody complains.
so the framework is: figure out your non-optional constraints, your optional constraints, the order you'd relax them, and then design the id generator. don't pattern-match to "snowflake!" because somebody used it at twitter. you might not need any of what twitter needed.
and please. for the love of distributed systems. don't make a microservice unless you have to. a function in your app code, a stored procedure in your db, a 4-byte file on local disk — these are all valid id generators. the box-on-an-architecture-diagram is not the goal. the function returning something unique every time it's invoked is the goal.
nothing is best. everything depends on the usecase.
✽ RECALL before you pattern-match to "snowflake!", what's the actual framework for designing an id generator?
list your non-optional constraints, your optional ones, and the order you'd relax them — then design. twitter relaxed strict monotonicity and got zero-service sortable ids; instagram also embedded shard info and got hot-shard rebalancing; cockroach relaxed sortability and got distributed write throughput; flickr relaxed "no central service" and got auto-increment for free; amazon relaxed "no wasted ids" and got cheap robust batching. and don't make a microservice unless something forces you to — a function in app code, a stored procedure, or a 4-byte file on disk are all valid id generators.