Database Locking
The fundamental question that we should always ask is "Why should we care about locking?" Because without that, it becomes some theoretical stuff someone just starts rambling about.
Why Do We Need Locks?
The reason you should care about locking is because you want to protect the sanity of the data. Which means your data should always make sense - you want to make sure that your data remains consistent and maintains its integrity.

For example, let's say I have a clap counter and the current value is 2. Two people clapped at the same time. My database would do count++ and count++ so final value should be 4. But it's possible that because two transactions were executing in parallel, the final value becomes 3 and not 4. Why would that be the case?
Because imagine both transactions read the value - they got 2 and 2, both updated +1 and +1, and then they wrote. So this way your final value becomes 3 and not 4. A classic multithreaded implementation where count++ is not atomic in nature.
So because you want to maintain the sanity of the data, you want to maintain the consistency of the data, you will have to make sure data correctness is of utmost importance - that's why locks are required.
Pessimistic Locking
Pessimistic locking is about you being pessimistic and when you want to make some changes, you take the lock beforehand, make the changes, and then release the lock - that's the whole idea. I am being pessimistic about the stuff that I'm about to do, so let me grab the lock beforehand so that nobody else can do whatever they want to do with my stuff and I'll do my thing.
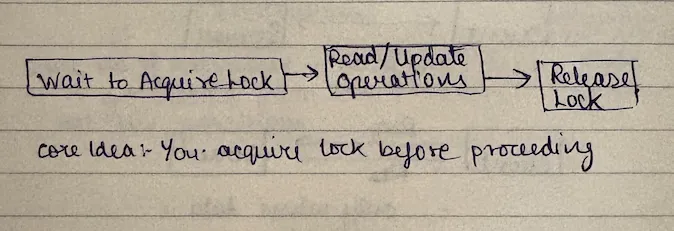
Almost always, the flow of your pessimistic locking would be:
- You wait to acquire a lock
- You do read, update, whatever you are doing
- You release the lock
This way, when you take this lock, this becomes a critical section which means only one transaction at a time can go into this. There are other ways to do it (reader-writer lock and whatnot), but we won't go into those details. For now, a primitive understanding that you certainly need to have is you acquiring the lock before you take action.
If there are 5 transactions wanting to update the same row, all 5 would be waiting. One of them would go in, take the lock, then release the lock, and then the next one would go and do it, and then the next one would go and do it. This way, it is kind of a bottleneck where everybody's waiting and one of them is going through and then doing it.
Mutexes are an example of pessimistic locking, and databases internally use mutexes to offer you pessimistic locking. The idea is they give you the tools and the ways to take pessimistic locks on stuff.
Types of Locks
There are two types of locking strategies:
- Shared locks - allows multiple readers to read while writer takes exclusive access
- Exclusive locks - what we'll focus on (since this is mostly used lol)
Exclusive locks: If my transaction holds an exclusive lock on a particular row, other transactions are neither allowed to read the row nor are allowed to modify the row.
Deadlock Risk
Like every other system that uses locking, this also suffers from the potential of deadlock.
What is a deadlock? Classic case:
- Row 1 is held by transaction T1
- Transaction T1 wants a lock on Row 2
- Row 2 is held by transaction T2
- Transaction T2 wants a lock on Row 1
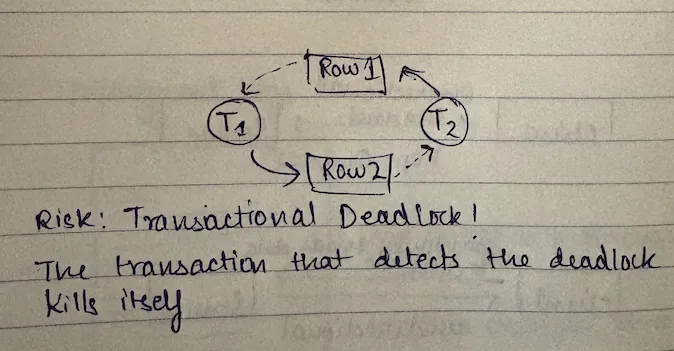
If the database engine grants T2 the lock on Row 1, it's a deadlock because neither transaction T1 can progress, neither transaction T2 can progress because there is a cycle - a classic deadlock.
How databases handle deadlock: Whenever you try to acquire a lock on a certain row, your database lock manager essentially maintains a resource dependency graph where it tracks which transaction owns lock on which set of rows and which set of rows transactions are interested in acquiring.
Whenever you try to acquire a lock, your database checks: "Hey if I grant this transaction lock on this row, would it lead to a deadlock?" If it does, the database literally kills the transaction which is trying to acquire the lock.
So your database makes sure that it never goes into a deadlock state - it prevents or rather it avoids the deadlock by making sure that it doesn't grant access to a row that might lead to a deadlock.
Practical Example: Collaborative To-Do List
Let's understand this with a simple example - a collaborative to-do list. Imagine there is a to-do list like Google Tasks and multiple people are updating it.

Imagine User 1 wants to mark items 1, 2, and 6 as done. User 2 wants to mark items 3, 4, and 6 as done. Both hit save at the very same instant - what's going to happen?
Using FOR UPDATE
So what you need to do is lock the rows to modify them. The way you lock the rows is by writing a regular select statement:
SELECT * FROM tasks WHERE id IN (1,2,6) FOR UPDATE;
When you end your select statement with FOR UPDATE, it means the transaction which is running this query gets an exclusive lock on the rows matched by the select query. So whichever rows are matched by the select query, your transaction would hold an exclusive lock on those rows.
What happens:
- Transaction 1 comes, acquires lock on rows 1, 2, and 6
- Transaction 2 comes and wants lock on rows 3, 4, and 6
- When Transaction 2 tries to acquire locks:
- Row 3 is not locked by anyone ✓
- Row 4 is not locked by anyone ✓
- Row 6 is locked by Transaction 1 ❌
So Transaction 2 will wait until Transaction 1 either commits or rolls back, even though only one of the rows is locked by Transaction 1. This transaction demands all three rows to be locked.
It's like "hey it's a to-do app but why do I have to do this? Can't I just update directly?" Think about it. The example I gave was marking 1,2,6 to be done or 3,4,6 to be done. Imagine there was a row where one user wants to select, another user wants to deselect it - which is why you have to make sure that you are acquiring the lock before you move forward.
Wait Behavior
When you say "it waits", it just waits for this transaction to commit or rollback. The connection is kept open, and the transaction is just waiting. It's not a busy wait; it is a sleepy wait. So it puts the transaction to sleep, and when the first transaction is committed or rolled back, the database engine signals the waiting transaction. It wakes up and then it proceeds further.
You can suddenly start seeing that it would start affecting throughput and whatnot. Yeah that's the disadvantage of locking, but correctness is more important than throughput.
SKIP LOCKED
But what if you don't want to wait? What if for your use case it's okay if you don't get all the rows? Say I want rows 3, 4, and 6 - what if it's okay if I don't get row 6? I just want rows 3 and 4.
In case any of the rows that I am asking for is locked by some other transaction, I'm OK skipping the locked rows.
SELECT * FROM tasks WHERE id IN (3,4,6) FOR UPDATE SKIP LOCKED;
The moment you do FOR UPDATE SKIP LOCKED, the output of the select query would be just rows 3 and 4 because 6 is already locked by Transaction 1.
There are cases where it is OK for you to skip the locked rows because you want to move faster. That's why you can skip them. By default behavior is waiting. But if it's OK for you to skip the locked rows, just skip the locked rows and move on.
NOWAIT
But what if your use case is "hey I don't want to wait no matter what" and I don't want to skip the locked rows?
Then in that case you have NOWAIT. Which means if I see any of the rows that I want to take lock on is locked by some other transaction, kill me.
SELECT * FROM tasks WHERE id IN (3,4,6) FOR UPDATE NOWAIT;
That is NOWAIT - I choose not to wait, I'm choosing to kill myself because I don't like waiting. You're like that kind of person who doesn't like waiting. You'd prefer killing your transaction rather than waiting.
There are cases - I have rarely seen NOWAIT, but it's quite possible. I've seen SKIP LOCKED more often than waiting, but NOWAIT is something that I've not seen much. But again, it's a tool that you have.
So your options are:
- Default behavior: Waiting
- SKIP LOCKED: Skip the locked rows and move on
- NOWAIT: Kill the transaction if any row is locked
Pattern Recognition
A simple mantra from some observations:
"Whenever you see fixed inventory and contention, think about locking. Fixed inventory + contention = locking."
Classic examples:
- COVID vaccination portal (2020) - people trying to book vaccination schedules, seats open up every day and everyone rushes to book. Fixed inventory, contention? Locking.
- IRCTC - train booking app, people trying to book tickets and get their seats. Fixed inventory, contention? Locking.
- Flash sales - Fixed inventory, contention? Locking.
That's the whole pattern. Think about all these scenarios - this is a common pattern that you would come across.
Optimistic Locking
Optimistic locking is the diametrically opposite brother of pessimistic locking.
While pessimistic locking is like "I will take the lock, without that I won't do a thing" (like that one engineer in your team who says "Without PRD I won't work"), optimistic locking is like "Let me start my exploration while the PRD comes in".

The idea is simple: I'm assuming that there won't be much contention, so if by default the contention is going to be rare, why should I take an overhead on my database to acquire the lock before I do anything?
The whole idea is the mindset:
- Pessimistic locking: "I want to be cautious, I will take a lock then proceed"
- Optimistic locking: "Hey, I don't want to be cautious. If it fails, then I'll take a look at it at that time because there's not much contention"
Which is why in case of optimistic locking you pay a penalty in case something breaks, and that penalty is heavy compared to pessimistic locking.
Two Things to Remember for Optimistic Locking:
- You do it when there is going to be not much contention on the same set of rows - contention needs to be rare
- You are okay paying a higher penalty in case there is contention
How to Implement Optimistic Locking
Think about a blog example. If you have a blog, you need to update the body, and each entity has a version column.
-- Blog table structure
blogs
id | title | body | version
b1 | - | - | 1
The whole idea of optimistic concurrency control is that it is highly unlikely that two people would be updating the same blog. This holds true because very likely you are the only one going to update your own blog, right? So you don't need pessimistic locking.
The core idea: When you are updating, you pass "Hey, I want to do this update, this is the version that I have". When you are updating, you also pass the version number. If version number matches, the updates are accepted. If the version numbers don't match, the update is rejected.
UPDATE blogs
SET title = 't1', version = version + 1
WHERE id = 'b1' AND version = 1;
Penalties of Optimistic Locking
Penalty number one: You have to read before you write because otherwise you won't get the correct version. You cannot just write directly because you have to pass the version number explicitly.
What happens with contention: Both transactions come, both read the blog to get the version number (they both see version 1). Then both try to update:
T1: UPDATE blogs SET title = 't1', version = 2 WHERE id = 'b1' AND version = 1;
T2: UPDATE blogs SET title = 't2', version = 2 WHERE id = 'b1' AND version = 1;
T1 succeeds (updates version to 2), T2 fails (because version is no longer 1).
This is going to happen when we are assuming contention is rare. This is a rare scenario - that's the fundamental assumption of OCC (Optimistic Concurrency Control).
Handling Failures
When the second transaction fails, depending on your use case, you either retry or relay the error:
- Retry: Read the new version and then decide to update it. For clap counter, retry makes sense.
- Relay error: "Hey, please refresh the page before you update, you are operating on an older version" - you see this on Substack or collaborative editing websites.
So this penalty or this behavior of penalty you decide for your business. But the core idea is, this is a rare occurrence. That's why you use optimistic over pessimistic.
When to Use What?
If it's not rare, if you are expecting high contention - pessimistic is a better choice.
There is no "optimistic is always better" or "pessimistic is always better" - it completely depends on:
- What you are building
- What your product experience is
- What your penalty experience is
- How costly your penalty is going to be
Decision matrix:
- Go for pessimistic when you have high contention
- Go for optimistic when contention is rare and you're okay with absorbing the penalty
Real-World Example: Airline Seat Booking
Let's understand locking with a practical example - 120 people trying to book 8 airline seats simultaneously.
Setup:
- 120 users, 8 seats (1-A through 2-B)
- Each user runs in a separate thread
- All trying to book at the same time
Approach 1: No Locking (The Problem)
-- Basic approach - race condition guaranteed
SELECT id, name FROM seats
WHERE trip_id = 1 AND user_id IS NULL
ORDER BY id LIMIT 1;
UPDATE seats SET user_id = ? WHERE id = ?;
What happens:
- Multiple threads read the same available seat (e.g., seat 1-A)
- All try to update the same row
- Only one succeeds, others fail silently
- Result: Only 4-5 seats get booked instead of 8
The race condition: Time gap between SELECT and UPDATE allows multiple transactions to read stale data.
Approach 2: SELECT FOR UPDATE (Blocking)
-- Add FOR UPDATE to lock the row
SELECT id, name FROM seats
WHERE trip_id = 1 AND user_id IS NULL
ORDER BY id LIMIT 1 FOR UPDATE;
UPDATE seats SET user_id = ? WHERE id = ?;
What happens:
- First transaction locks seat 1-A
- 119 transactions wait for that lock
- When first transaction commits, all 119 wake up
- Database re-evaluates the query - now seat 1-B is first available
- All 119 try to lock seat 1-B, one succeeds, 118 wait...
- Result: All 8 seats get booked in perfect order (1-A, 1-B, 1-C...)
Trade-off: Correct but slow (~489ms) - transactions spend most time waiting.
Approach 3: SKIP LOCKED (Non-blocking)
-- Skip locked rows, don't wait
SELECT id, name FROM seats
WHERE trip_id = 1 AND user_id IS NULL
ORDER BY id LIMIT 1 FOR UPDATE SKIP LOCKED;
UPDATE seats SET user_id = ? WHERE id = ?;
What happens:
- Transaction 1 locks seat 1-A
- Transaction 2 finds 1-A locked, skips it automatically, locks 1-B
- Transaction 3 skips 1-A and 1-B, locks 1-C
- 8 transactions get seats, 112 fail immediately
- Result: All 8 seats booked, very fast (~23ms)
Key insight: Seats are picked in order but allocated in random order due to thread scheduling.
The Three-Way Comparison
| Approach | Seats Filled | Speed | Correctness |
|---|---|---|---|
| No Locking | 4-5 (random) | Very fast | ❌ Race conditions |
| FOR UPDATE | 8 (all) | Very slow | ✅ Correct |
| SKIP LOCKED | 8 (all) | Fast | ✅ Correct |
Key Takeaways from the Example
The Fairness Question: What if we want user 1 to get seat 1, user 2 to get seat 2? Answer: Don't use threading! Use a simple loop. Most problems don't actually need the complexity of multi-threading.
It's easy to write multi-threaded programs, difficult to write correct ones, even harder to write fair, efficient, and correct ones.