Caching : Thundering Herd and Request Hedging
Caching: It's Not Just About Memory
Myth-busting time: Caching doesn't mean in-memory. I see this confusion everywhere.
We accept data staleness in exchange for avoiding expensive operations. Every time you cache something, you're saying 'I'd rather serve data that might be 5 minutes old than wait 2 seconds for a database query
What Caching Really Means
Cache = saving expensive operations. That's it.
Expensive operations include:
- Database queries with 14 table joins
- Network calls to external services
- Complex computations
- File system reads
You can cache:
- In memory (Redis)
- On disk (API server's unused SSD)
- In browser (localStorage)
- At CDN edge
The Under-utilized Cache Location
Here's something nobody talks about - your API server's disk is sitting there doing nothing.
You spin up an EC2 instance:
- 4GB RAM (fully utilized)
- 20GB SSD (5% utilized)
Why not cache on that SSD? It's faster than network calls to Redis, costs nothing extra, and the space is already paid for.
But wait - multiple API servers means cache inconsistency! Which is why we usually centralize with Redis. But for read-heavy, rarely-changing data? Disk cache works beautifully.
Cache Stampede & Request Hedging
The fundamental question we should always ask is: "What happens when your cache expires and 1000 requests hit simultaneously?"
Answer: Your database dies, your site goes down, and you get paged at 3 AM. Let me show you how to prevent this nightmare scenario.
The Cache Stampede Problem
Picture this: You have a popular blog post cached in Redis. The cache expires. Suddenly, 1000 concurrent requests hit your API at the exact same moment.
What happens?
- All 1000 requests check Redis → cache miss
- All 1000 requests query the database
- Database connection pool gets overwhelmed
- Database melts under load
- Site goes down
- You're now debugging at 3 AM while your users are angry
This is called a cache stampede or thundering herd problem, and it's one of the most common ways high-traffic applications fail.
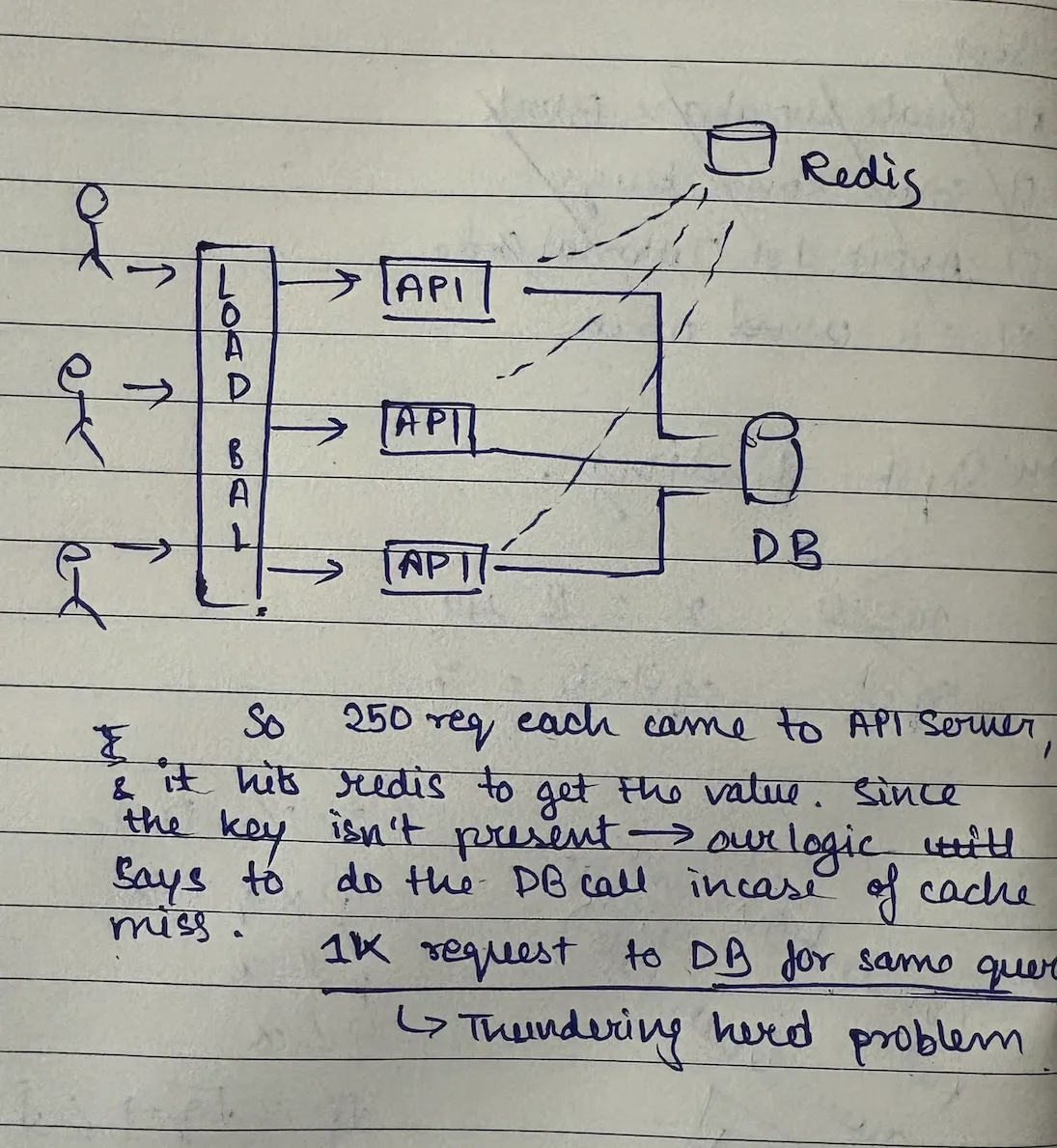
Why is this so dangerous? Even if you have database connection pooling (which you should), making N identical expensive queries to your database for the same data doesn't make any sense. It's pure waste that can bring down your entire system.
The Real-World Impact
This isn't some theoretical problem I'm throwing at you. This is literally what CDNs solve every single day.
Think about it: CloudFlare, AWS CloudFront, and every other CDN faces this exact problem. When a cached resource expires and thousands of requests come in simultaneously, they can't all hit the origin server. The origin would die instantly.
CDNs use sophisticated request hedging to ensure that only ONE request goes to the origin while everyone else waits for that response. This is production-tested at massive scale.
The Solution: Request Hedging (Smart Debouncing)
Here's the elegant solution - and this is literally the pseudo-code you'd write:
# Pseudo-code that would work if you saved this as .py
sem_map = {} # Use thread-safe implementation
res_map = {} # Temporary result storage
def get_blog(k):
# First, try cache
v = cache.get(k)
if v is not None:
return v
# Check if someone else is already fetching this
s = sem_map.get(k)
if s:
s.wait() # Wait for someone else to do the work
v = res_map.get(k) # Get the result they fetched
return v
else:
# I'm the first one - I'll do the work
sem_map[k] = new_semaphore()
sem_map[k].block() # Block others
# Do the expensive work
v = db.get(k)
cache.put(k, v)
res_map[k] = v # Store temporarily for waiting requests
# Signal that I'm done
sem_map[k].signal()
sem_map.remove(k)
return v
Implementation Details That Matter
Why the Temporary Result Map?
You might wonder: "Why not just make waiting requests hit the cache again after the signal?"
Because that creates unnecessary load! If everyone waits and then immediately hits the cache again, you've just created another stampede on your cache layer.
The res_map is a temporary local storage (5-minute TTL) that holds the result just long enough for waiting requests to grab it directly. This eliminates the extra cache round-trip.
When You Actually Need This
"I've been using Redis for years and never needed this!"
Fair point. This isn't some academic exercise. You need request hedging when you have:
- High traffic with shared expensive resources
- Cache expiration happening under concurrent load
- Database queries that take >100ms
- Flash sale scenarios or viral content
CDN Use Case (Real-World Example)
CDNs face this constantly:
- Origin: Your S3 bucket or API server
- Cache: CDN edge servers worldwide
- Problem: Popular resource expires, 10,000 requests hit one edge server
- Solution: Only ONE request goes to origin, others wait
This pattern has prevented countless outages for companies you use every day.